

CZEMU OFIARY NIE BRONIĄ SIĘ PRZED MOBBINGIEM?
W wielu miejscach pracy istnieje kultura mobbingu. Ma ona różne źródła. Jednym jest zachodni model zarządzania w warunkach ostrej konkurencji i walki o przetrwanie, który widzimy w korporacjach. Drugim jest wywodzący się z PRL duch „Pana i Władcy”, który unosi się nad urzędami, uniwersytetami i innymi instytucjami publicznymi. Trzecim jest model małej prywatnej firmy, w której właściciel uważa, że może wszystko, bo to jego. Łączą je dwa elementy: 1) niszczą człowieka; 2) trwają tylko tak długo, jak długo wszyscy na to pozwalają. Gdy pierwsza osoba zauważy, że „król jest nagi”, najcześciej pęka on, jak balon. Dotyczy to w tej samej mierze mówiących korposlangiem menadżerów, konserwatywnych profesorów i właścicieli małych firm z prowincji. W praktyce obserwuję również mobbing w firmach rodzinnych.
Jaka jest definicja mobbingu?
Definicja mobbingu zawarta jest w art. 943 § 2 kodeksu pracy. Mobbing oznacza:
- działania lub zachowania;
- dotyczące pracownika lub skierowane przeciwko pracownikowi;
- polegające na uporczywym i długotrwałym;
- nękaniu lub zastraszaniu pracownika;
- wywołujące u niego zaniżoną ocenę przydatności zawodowej;
- powodujące lub mające na celu poniżenie lub ośmieszenie pracownika, izolowanie go lub wyeliminowanie z zespołu współpracowników.
Czy mobbing musi trwać długo?
Istotne jest, że mobbing nie jest jednorazowym zachowaniem, ale działania muszą być uporczywe i długotrwałe. Oczywiście, to określenie nie jest jasne. Zdaniem Sądu Najwyższego (sprawa I PK 176/06) „Długotrwałość nękania lub zastraszania pracownika musi być rozpatrywana w sposób zindywidualizowany i uwzględniać okoliczności konkretnego przypadku. Nie jest zatem możliwe sztywne wskazanie minimalnego okresu niezbędnego do zaistnienia mobbingu. Dla oceny długotrwałości istotny jest moment wystąpienia wskazanych w przepisach skutków nękania lub zastraszania pracownika oraz uporczywość i stopień nasilenia tego rodzaju działań.”
W uzasadnieniu innego wyroku SN w sprawie III PSKP 30/22 czytamy, że „generalnie przyjmuje się, że długotrwały terror psychiczny w miejscu pracy, to co najmniej sześć miesięcy. Nie jest to wszakże żadna sztywna granica.”
W tym samym uzasadnieniu Sąd Najwyższy pokazał, jak należy w kontekście długotrwałości rozumieć uporczywość mobbingu: „Długotrwałość zachowań uznawanych za mobbing należy rozpatrywać jednocześnie z ich uporczywością, która rozumiana jest jako znaczne nasilenie złej woli ze strony mobbera. Uporczywość oznacza rozciągnięte w czasie, stale powtarzane i nieuchronne (z punktu widzenia ofiary) zachowania, które są uciążliwe i mają charakter ciągły. Przesłanki „uporczywości” i „długotrwałości” wzajemnie na siebie oddziałują. Nie da się ich rozważać oddzielnie. Dlatego intensyfikacja negatywnych zachowań skłania do uznania za długotrwały okresu krótszego niż w przypadku mniejszego ich nasilenia.”
Czy skutek mobbingu musi wystąpić?
Tak, skutek mobbingu musi wystąpić. Długotrwałe i uporczywe działanie mobbera musi wywołać skutek w postaci zaniżonej oceny własnej przydatności zawodowej przez jego poniżenie, ośmieszenie, izolowanie lub wyeliminowanie z zespołu. Więcej o koniecznych skutkach mobbingu przeczytacie w uzasadnieniu wyroku SN z dnia 1 czerwca 2023 w sprawie I PSK 22/22.
Jeśli ten skutek nie został wywołany, mówimy o zachowaniu nieprawidłowym lub noszącym znamiona mobbingu, ale jeszcze nie o mobbingu. To trochę, jak morderstwem – jeśli ofiara przeżyła, to nie ma morderstwa, chociaż możemy mówić o jego usiłowaniu lub ciężkim uszkodzeniu ciała itd.
Mobbing jest wyraźnie dostrzegany i kwalifikowany jako problem, z którym należy walczyć. Polecam Wam sporządzony przez Forum Odpowiedzialnego Biznesu Raport o mobbingu.
Zachowania zbliżone do mobbingu
Młodsze pokolenie jest bardziej wrażliwe, ale czy potrafi stawiać granice?
Koniecznie też trzeba zwrócić uwagę na przesuwającą się granicę społecznych oczekiwań i tolerancji. Można powiedzieć, że wszyscy robimy się coraz bardziej wrażliwi i to, co jeszcze niedawno wydawało się zupełnie normalne (przynajmniej niektórym), dzisiaj może być uznane za działanie mobbingowe. Ta zmiana percepcji daje się dostrzec w szczególności w zespołach mieszanych „wielopokoleniowych”.
Gdy ja pracowałem na Uniwersytecie, mój przełożony miał w zwyczaju zdzwonić do mnie (i do wszystkich innych) wieczorami, np. koło 21. Dla niego było to normalne. Myślę, że nawet mu nie przyszło do głowy, że jest to co najmniej niestosowne. Moja ówczesna małżonka – młoda lekarka w trakcie specjalizacji i doktoratu – dziwiła mi się, że w ogóle odbieram telefon o tej godzinie.
Polityka kadrowa jako narzędzie wywierania wpływu
To samo dotyczyło polityki Uniwersytetu w zakresie zatrudniania pracowników. Cały etat był nagrodą zarezerwowaną dla tych, którzy już się złamali i poddali, przestali oczekiwać normalności. Normą był ułamek etatu oraz nadgodziny wyrabiane głównie w weekendy. Umowa była zawierana oczywiście na rok, umowa na czas nieokreślony była dla młodszej kadry rzadkością.
Oczekiwano przy tym pełnej dyspozycyjności. Natomiast „przeżycie” zapewniano przez uznaniowy system stypendialny lub wcześniej wspomniane nadgodziny i pracę w weekendy. Były one przyznawane niemal jak przywilej, gdyż są nieco lepiej płatne. Nie pozwalało to planować niczego, ani myśleć o kredycie na mieszkanie. W oczach starszej kadry było to normalne, „bo oni też tak mieli”. Ten sam przełożony, który blokował przyznanie pełnego etatu młodemu pracownikowi, oczekiwał od niego wdzięczności i lojalności za napisanie pozytywnej opinii do wniosku o stypendium.
Czy to mobbing? Oceńcie sami. O tym, jak wygląda mobbing na uniwersytetach już kilka razy pisałem. Podobnie, opisałem moje doświadczenia z uniwersytecką komisją antymobbingową na jednej z łódzkich uczelni. Możecie przeczytać również mój artykuł o fałszywych oskarżeniach o mobbing i o tym, jak się przed nimi bronić.
Jak się bronić przed mobbingiem?
Co musisz zrobić?
Po pierwsze – słuchaj się swojej intuicji. Ona najczęściej mówi prawdę w przeciwieństwie do haseł wiszących na stołówce dla pracowników. Odczucie niepokoju, dyskomfortu, poczucie, że coś jest nie tak jest sygnałem, że zachodzi niezgodność miedzy oficjalną narracją, a tym, co dzieje się w rzeczywistości.
Po drugie – skonsultuj się z prawnikiem, który ma doświadczenie w sprawach o mobbing. On będzie w stanie ocenić, czy mamy już do czynienia z mobbingiem, czy ta granica nie została jeszcze przekroczona. Adwokat oceni, czy poczucie przekroczenia granic wynika z nadmiernej wrażliwości (bo i to się przecież zdarza), czy jest sygnałem, że mobbing rzeczywiście zaistniał.
Po trzecie – wspólnie z adwokatem przygotujcie strategię. Określicie cele, przygotujecie się do działania, zbierzecie dowody.
Po czwarte – wybierzecie najlepsze możliwe narzędzie do osiągnięcia wyznaczonego celu. Raz będzie to działanie przed działającą u pracodawcy komisją antymobbingową. Kiedy indziej będzie to wypowiedzenie umowy o pracę z winy pracodawcy i wystąpienie do sądu pracy. W innym przypadku konieczne będzie zainicjowanie postępowania karnego przed prokuraturą lub wystąpienie do sądu cywilnego z powództwem związanym z naruszeniem dóbr osobistych.
Kiedy pojawia się mobbing?
Mobbing pojawia się, gdy zajdą łącznie dwa warunki: 1) skłonności psychiczne sprawcy; 2) subiektywne przekonanie sprawcy, ofiary i otoczenia, że sprawca może to robić. O ile na warunek pierwszy nie mamy wpływu, to warunek drugi daje nam ogromne pole do działania. Bo tak naprawdę „król jest nagi” – jak w bajce. Mobbing to nowotwór na organizmie organizacji. On rozwija się latami, czasem tak wolno, że wszyscy się do niego przyzwyczajają.
Ale mobbing to też teatr. To serial, który będzie leciał tylko tak długo, jak długo wszyscy jego aktorzy będą chcieli w nim grać. Wystarczy, że wyłamie się jeden, a pozycja mobbera zawali się, jak domek z kart.
Czemu więc mobbing trwa?
Czemu nie mówimy mobbingowi „stop”?
To najciekawszy element. Najtrudniejszy i najsmutniejszy. Wynika on ze znanych psychologii mechanizmów opisujących zachowania jednostki i „stada”. Należą do nich:
- Przekonanie ofiary, że: a) tak być musi; b) że jest słabsza; c) że nie wolno jej chcieć zmiany; d) że jest winna; e) że musi „nieść ten krzyż” – z którym się przez lata zrosła;
- Ten ostatni element – zbudowanie narracji o sobie wokół własnego cierpienia jako punktu centralnego i budowa opowieści o poszukiwaniu własnej wartości i swojego miejsca na świecie wokół wywołanej przez mobbera patologii – jest decydujący. W skrajnych przypadkach usuniecie mobbingu będzie równoznaczne z podważeniem narracji o sobie samym i swojej roli, swoim znaczeniu;
- Dochodzi do tego efekt utopionych kosztów, który przejawia się w tym, że występując przeciwko mobbingowi musielibyśmy zanegować własną bierność, cierpienia i wyrzeczenia, na które godziliśmy się przez lata. Dla wielu osób jest to zbyt trudne;
- Efekt stada – ten, kto pierwszy podniesie głowę uderza w szereg podobnych narracji innych osób, innych ofiar. One mogą woleć tolerować patologię dalej, byle tylko ktoś inny nie pokazał im, że do tej pory robiły to bez potrzeby. Zawsze znajdzie się też ktoś taki, kto godzi się na patologię tylko od tym warunkiem, by inni nie mieli lepiej od niego. Zżyje się on z nią i będzie jej strażnikiem. Kto oglądał film „Django” i pamięta straszną, ale genialną rolę Samuela L. Jacksona, ten wie, co mam na myśli;
- Strach przed przewagą mobbera – najczęściej jest to ktoś bardziej wpływowy od ofiary, a więc: a) ma układy; b) ma pieniądze; c) tak go na dobrych prawników itp. W praktyce przewaga ta działa tylko tak długo, jak ofiara w nią wierzy. W praktyce nie wytrzymuje konfrontacji z rzeczywistością.
Czemu ofiary mobbingu boją się prosić o pomoc?
Wiele osób obawia się pójść do adwokata, gdyż boją się, że okaże się on znajomym mobbera / pracodawcy. Adwokat powinien o tym od razu poinformować i zachować rozmowę w tajemnicy. Ale niektórzy boją się „układów” tak bardzo, że nie decydują się na konsultację. Obawiają się opowiedzieć o swojej sytuacji, gdyż nie chcą, żeby dotarło do sprawcy, że odważyli się sięgnąć po pomoc. Wyszedłem tym obawom naprzeciw. Jak? Przeczytajcie na końcu artykułu o naszych procedurach i gwarancjach bezpieczeństwa dla klientów.
Zastosowanie modelu podejmowania decyzji Fogga do analizy procesu decyzyjnego w przedmiocie podjęcia walki z mobbingiem
O tym, kiedy podejmujemy decyzję, mówi model podejmowania decyzji Fogga. Ja wykorzystałem model Fogga do rozwinięcia opisu procesu decyzyjnego i ustalenia parametrów decyzji oraz pokazałem, jak mogą ten proces zaburzać błędy poznawcze (m.in. ww. efekt utopionych kosztów oraz myślenie tunelowe). Przeanalizowałem również proces podejmowania decyzji o zakończeniu współpracy między wspólnikami z wykorzystaniem modelu Fogga. Uważam, że wnioski w nim zawarte są w dużej mierze aktualne również przy podejmowaniu decyzji sprzeciwieniu się mobbingowi.
Jakie są największe błędy pracowników, którzy sprzeciwiają się mobbingowi?
Walka z mobbingiem to proces, który ma swój początek, cele, przebieg i koniec. W tym czasie można popełnić wiele błędów, które te proces spowalniają lub mogą go zatrzymać. Do najpoważniejszych należy:
- brak jasnego określenia celów: odejście z pracy i walka o odszkodowanie / pozostanie i walka zmianę;
- użycie narzędzi, które nie służą do osiągnięcia danego celu w ogóle lub nie są skuteczne w danych okolicznościach;
- przesadna obawa przed eskalacją;
- konsultacje „z każdym”, ale nie z prawnikiem zajmującym się sprawami o mobbing. Pytamy sąsiadów, kolegów, rzecznika praw pracownika (który pracuje dla pracodawcy!), sztuczną inteligencję, ale nie pytamy tego, który może nam faktycznie pomóc, ma doświadczenie i nie ma konfliktu interesów – dobrego adwokata.
Konsultacje z AI mogą wzmacniać błędne założenia i prowadzić do radykalizacji
Wiele osób trafia do mnie z pełnym przeświadczeniem, że są ofiarami mobbingu. Przynoszą mi „gotowe listy” argumentów i żądań. Nie szukają jednak profesjonalnej pomocy prawnej, ale potwierdzenia. Szukają potwierdzenia wniosków z rozmowy z modelem sztucznej inteligencji. Widzę wpływ AI na radykalizację postaw w sporach rodzinnych. Obserwuję wpływ modeli LLM na powstawania myślenia tunelowego w sporach między wspólnikami. Najczęściej jednak mam do czynienia z tym zjawiskiem w sprawach pracowniczych.
Konsultacje z modelami sztucznej inteligencji mogą – wskutek jej halucynowania i tzw. tendencji do generowania sprzężenia zwrotnego – prowadzić do wzmocnienia podstawowego błędu atrybucji lub np. do powstania sprzężonego błędu konfirmacji (to moja autorska koncepcja), którą rozwinąłem w tym tekście.
Intensywne konsultacje z modelami LLM mogą prowadzić do:
- radykalizacji przekonań,
- odrzucaniu argumentów przeczących z góry przyjętej tezie;
- dostrzegania potwierdzeń przyjętej tezy również tam, gdzie ich nie ma;
- odrzucania możliwości porozumienia;
- wykluczania dobrej woli drugiej strony;
- akceptacji agresji jako rozwiązania.
Odczuwasz mobbing? Skontaktuj się z nami
Jeśli czujesz, że potrzebujesz pomocy, odezwij się do nas. Nie wiesz, ile to kosztuje? Odpowiemy wprost: pełna konsultacja to koszt 400 PLN. I to jest jedyny pewny koszt, jaki poniesiesz.
Podczas rozmowy ustalimy, czy problemy, z którymi się mierzysz spełniają kryteria mobbingu. Przedstawimy Ci możliwe działania oraz określimy ich koszty i czas realizacji.
Zanim to jednak nastąpi, obejmiemy Cię naszymi procedurami bezpieczeństwa: Onboardingu i NDA.
Onboarding i poszukiwanie konfliktu interesów
W Kancelarii Jakubiec i Wspólnicy przyjęliśmy najwyższe standardy naszego zaangażowania i profesjonalizmu. Wykraczają one daleko poza to, czego wymaga od nas kodeks etyki adwokackiej. Służy temu procedura onboardingu, w ramach której aktywnie poszukujemy ewentualnych problemów i okoliczności, które mogłyby wpływać na naszą współpracę. Sprawdzamy powiązania zawodowe, biznesowe, towarzyskie i rodzinne wszystkich członków naszego zespołu, by mieć pewność, że nie istnieją żadne przeciwskazania, byśmy w pełni zaangażowali się w Twoją sprawę. Chronimy w ten sposób Ciebie – chcemy wykluczyć konflikt interesów już na samym początku.
Jeśli okaże się, że takie powiązania istnieją, natychmiast Cię o tym poinformujemy i wspólnie podejmiemy decyzję, czy można je zniwelować (np. przez wyłączenie od prowadzenia sprawy prawnika, który ma powiązania z drugą stroną), czy też należy współpracę zakończyć. Wówczas masz pewność, że wszystko, czego się dowiedzieliśmy pozostanie tajemnicą, zwrócimy Ci wszystkie dokumenty i dowody oraz polecimy inną kancelarię.
Z badania konfliktu interesów dostaniesz pisemny raport. Będzie w nim kara umowna płatna dla Ciebie, gdyby okazało się, że złożyliśmy świadomie nieprawdziwe oświadczenie.
Umowy NDA Kancelarii z Klientem
Podpisujemy z naszymi klientami umowy o zachowaniu poufności, w których zastrzegamy kary umowne na rzecz klientów. Zdecydowałem sie na to nie dlatego, że wątpię w mój zespół. Wprost przeciwnie! Zrobiłem to, bo jestem absolutnie pewny profesjonalizmu i lojalności wszystkich moich współpracowników i dlatego obok Twojego zaufania „kładę na stole” własne pieniądze.
Bezpieczeństwo naszych klientów
Najważniejsze jest dla nas to, żeby nasi klienci mogli czuć się z nami bezpiecznie. Jak widzisz, dla nas to nie tylko słowa – to konkretne zobowiązania i procedury. U nas nie ma miejsca na jakiekolwiek watpliwości po stronie klienta, czy adwokat jest po jego stronie. Jesteśmy tylko po Twojej stronie albo nie bierzemy sprawy wcale.
Odezwij się do nas. Z nami możesz czuć się bezpiecznie:
kancelaria@jakubieciwspolnicy.pl lub możesz napisać bezpośrednio do mnie: jakubiec@jakubieciwspolnicy.pl
Możesz też do mnie zadzwonić: 536270935 – to jest mój numer telefonu, który sam odbieram.
Rozumiem, że może zależeć Ci na całkowitej dyskrecji. Daj znać, a spotkamy się zupełnie sami, poza godzinami pracy Kancelarii. Możemy przeprowadzić również rozmowę w formie online.
PUŁAPKI MYŚLENIA I ICH WPŁYW NA DECYZJE W MODELU FOGGA
W kilku poprzednich tekstach przedstawiłem niektóre błędy poznawcze (pułapki myślenia), m.in. podstawowy błąd atrybucji, myślenie tunelowe i moją autorską koncepcję sprzężonego błędu konfirmacji (Coupled Confirmation Bias). Pisałem o nich głównie w kontekście ich wpływu na dynamikę sporu, co obserwuję w mojej codziennej pracy. Teraz chcę pójść krok dalej i pokazać, jak te same mechanizmy wpływają na proces podejmowania decyzji w modelu Fogga.
Czym są błędy poznawcze?
Błędy poznawcze to inaczej błędy lub pułapki myślenia. Pojęcie to wprowadził do języka powszechnego Daniel Kahneman. Ten wybitny psycholog opublikował książkę „Pułapki myślenia. O myśleniu szybkim i wolnym„. Opisał w niej mechanizmy, które dotyczą nas wszystkich. Nie dlatego, że coś z nami nie tak. Te mechanizmy mają swoje istotne funkcje. Upraszczają wiele spraw. Pozwalają np. zachować energię, rozwiązać dany problem w sposób wystarczający na tyle, żeby zająć się następnym. Ale w złożonych relacjach społecznych sprawiają, że błędnie oceniamy rzeczywistość, tworzymy w głowie nieprawdziwe narracje i w efekcie podejmujemy błędne decyzje.
Jakie znamy błędy poznawcze?
Błędów poznawczych jest sporo, a pewnie wielu jeszcze nie odkryliśmy. Ja tu przedstawię krótko tylko z nich:
1. Błąd potwierdzenia (confirmation bias)
2. Podstawowy błąd atrybucji (Fundamental Attribution Error)
3. Błąd status quo (Status quo bias)
4. Efekt utopionych kosztów (sunk costs fallacy)
5. Sprzężony błąd konfirmacji (Coupled Confirmation Bias) – moja autorska koncepcja (i jej rozwinięcie), która jest wyłącznie hipotezą i wymaga rozwinięcia i empirycznego potwierdzenia.
6. Myślenie tunelowe (tunnel vision), które nie jest samo w sobie błędem poznawczym, ale mechanizmem systemowym.
Wpływ błędów poznawczych na podejmowanie decyzji choćby w kontekście zawierania porozumień jest przedmiotem pogłębionych badań naukowych. Część z nich jest uznana za hamujące, inne za wzmacniające. Ten podział jest przydatny do wyciągnięcia dalszych wniosków.
Poniżej przedstawię kolejno:
- tryb podejmowania decyzji w modelu Fogga i
- parametry podjętej decyzji.
Dopiero potem pokażę, jak wybrane błędy poznawcze mogą wpływać zarówno na to, czy w ogóle podejmiemy decyzję, jak i na jej treść.
Podejmowanie decyzji w modelu Fogga. Triada decyzyjna
Model podejmowania decyzji Fogga jest prosty i elegancki. Obejmuje on triadę decyzyjną, na którą składają się: 1) motywacja; 2) wykonalność i 3) wyzwalacz. Jeśli chcecie dowiedzieć się o tym modelu więcej, więcej, odsyłam Was do artykułu, który napisałem o zastosowaniu modelu Fogga do analizy mechanizmu podejmowania decyzji i zakończeniu współpracy / wyjścia ze spółki. Tam napisałem więcej o motywacji jako stanie afektywnym o podłożu biologicznym, który ma dwa kierunki: pozytywy i negatywny. Teraz zobaczmy graficzne przedstawienie modelu decyzyjnego Fogga:
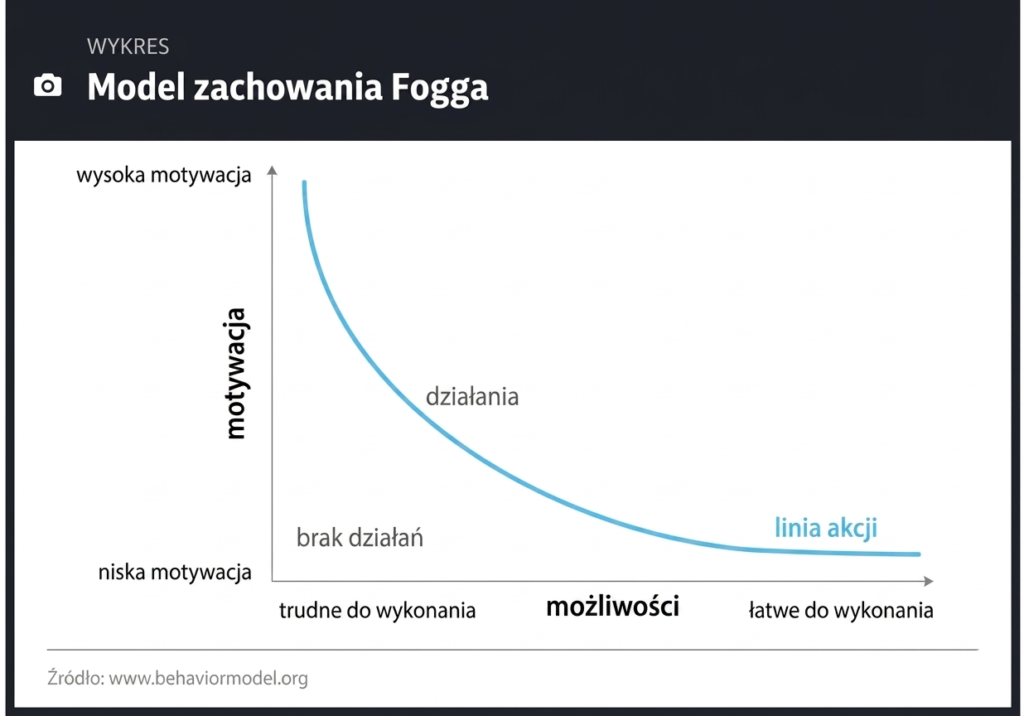
Zapamiętajmy z niego, że aby doszło do decyzji wszystkie 3 elementy 1) motywacja, 2) możliwość i 3) wyzwalacz muszą wystąpić: łącznie. Omówiłem to już szerzej w poprzednim tekście.
Teraz tylko postawię pytanie:
Czym jest „możliwość” w ujęciu Fogga?
Ja rozumiem możliwość jako właściwość, której cechy lepiej oddaje słowo „wykonalność”. Tego wątku nie rozwinąłem w poprzednim artykule, dlatego robię to teraz.
Wykonalność w modelu Fogga -w moim rozumieniu – jest wypadkową subiektywnie postrzeganych: 1) własnych możliwości i 2) trudności zadania.
Liczy się wyłącznie percepcja decydenta. Może on oczywiście źle ocenić sytuację wskutek błędu poznawczego lub błędu danych. Co ciekawe, błąd może prowadzić w efekcie do podjęcia korzystnej decyzji. Wyobraźmy sobie, że mam niepełne lub nieprawdziwe dane. Działając pod wypływem błędu logicznego lub błędu kognitywnego wyciągam z nich nieprawidłowe wnioski. Wnioski te byłyby ocenione jako prawidłowe, gdybym miał dostęp do pełnych lub prawdziwych danych, a nie działałbym pod wpływem błędu.
Można to podsumować jednym zdaniem: triada Fogga wpływa na podjecie decyzji, co nie jest tożsame ze sposobem jej realizacji. Sposób realizacji wcześniej podjętej decyzji jest opisywany przez parametry decyzji (o nich niżej).
Jakie są rodzaje decyzji?
Proponuję, by decyzjom analizowanym przez pryzmat sposobu ich wykonania przypisać 3 parametry. Decydują one o sposobie ich realizacji.
3 parametry decyzji to: wektor, dynamika i determinacja (zastanawiam się, czy nie lepiej nazwać ją pędem).
Pierwszym parametrem jest wektor. Jego punktem odniesienia niech będzie stan obecny. Jego wartość to 0 lub 1. Niech 0 oznacza tendencję do pozostania w obecnym układzie, a 1 jest dążeniem do zmiany.
Drugim parametrem jest dynamika. Wyróżnijmy 2 wartości dynamiki: (+) i (-), gdzie (+) oznacza, że decyzja skutkuje działaniem, a (-) biernością.
Trzecim parametrem jest determinacja (L) i (H), gdzie (L) – oznacza niską (ang low) determinację, a (H) oznacza wysoką (ang. high) determinację.
Wektor określa stosunek do stanu aktualnego i jego zmiany. Decyzja o obronie status quo lub jego zmianie może być realizowana – zależnie od okoliczności – przez bierność lub działanie (dynamika + lub –). Determinacja jest funkcją gotowości zaangażowania, przez które rozumiem wypadkową:
1) gotowości poniesienia kosztów (finansowych, wizerunkowych, organizacyjnych, energetycznych, a nawet biologicznych) oraz
2) tolerancji ryzyka.
Wektor, dynamika i determinacja stanowią uproszczony model heurystyczny, stworzony przeze mnie (a przynajmniej nie znam publikacji, które się tymi parametrami posługują – poza wyżej wspomnianymi biasami hamującymi i wzmacniającymi) na potrzeby tego opisu. Jego użyteczność wymaga z pewnością badań – jest to obecnie wyłącznie model hipotetyczny. Zaznaczam też, że ludzka psychika to nie matematyka, ale właśnie matematyka pozwala -paradoksalnie – zrozumieć psychikę lepie
Tabela 1: 3 parametry decyzji
| Parametr decyzji | Wartość parametru | Opis i znaczenie parametru |
|---|---|---|
| Wektor | 0 | Oznacza tendencję do utrzymania stanu obecnego. Decydent interpretuje sytuację jako taką, w której lepiej pozostać przy status quo. |
| 1 | Oznacza dążenie do zmiany stanu obecnego. Decydent uznaje, że obecny układ wymaga modyfikacji lub porzucenia. | |
| Dynamika | + | Decyzja realizowana przez działanie. Oznacza aktywne wykonanie czegoś, co ma doprowadzić do utrzymania lub zmiany stanu. |
| – | Decyzja realizowana przez bierność. Oznacza powstrzymanie się od działania jako sposób osiągnięcia celu (utrzymania lub zmiany). | |
| Determinacja | L | Niska determinacja. Oznacza ograniczoną gotowość poniesienia kosztów i niską tolerancję ryzyka. Decyzja jest słaba, łatwa do zmiany. |
| H | Wysoka determinacja. Oznacza dużą gotowość poniesienia kosztów (finansowych, emocjonalnych, organizacyjnych, biologicznych) i wysoką tolerancję ryzyka. Decyzja jest silna i stabilna. |
Użycie wyżej wymienionych 3 parametrów pozwala nam wyróżnić 8 rodzajów decyzji.
Tabela 2: 8 rodzajów decyzji
| Numer porządkowy rodzaju decyzji | Wektor | Dynamika | Determinacja | Opis decyzji | Przykład |
|---|---|---|---|---|---|
| 1 | 0 | – | L | Decyzja o utrzymaniu status quo przez bierność z niską determinacją | Decyduję, że jeszcze pośpię |
| 2 | 0 | – | H | Decyzja o utrzymaniu status quo przez brak działania z wysoką determinacją | Siedząc na drzewie decyduję, żeby się nie ruszać, żeby nie spaść |
| 3 | 0 | + | L | Decyzja o utrzymaniu status quo przez działanie z niską determinacją | Decyduję, że odganiam kota, który mnie budzi |
| 4 | 0 | + | H | Decyzja o utrzymaniu status quo przez działanie z wysoką determinacją | Bronię córkę przed napastnikiem |
| 5 | 1 | – | L | Decyzja o zmianie przez bierność z niską determinacją | Nie podlewam kwiatów, których nie lubię, żeby uschły |
| 6 | 1 | – | H | Decyzja o zmianie przez bierność z wysoką determinacją | Decyzja o zaniechaniu ratowania kogoś, gdy chcę, żeby się utopił |
| 7 | 1 | + | L | Decyzja o zmianie przez działanie z niską determinacją | Chcę obciąć kotu pazury |
| 8 | 1 | + | H | Decyzja o zmianie przez działanie z wysoką determinacją | Chcę uciec z więzienia |
Dodajmy, że:
- decyzje o wektorze 0 (zachowanie status quo) oraz
- decyzje o dynamice ujemnej (-) o osiągnięciu celu przez bierność
nie oznaczają w żadnym razie braku decyzji. To nie jest to samo. Decyduję się siedzieć cicho i nieruchomo, żeby ktoś mnie nie znalazł. Decyzja o tym nie jest tym samym, co zewnętrznie dostrzegana bierność spowodowana np. apatią lub ambiwalentnym stosunkiem do danego stanu.
Tak samo trzeba wspomnieć, że
- decyzja o zmianie (Wektor 1) nie może być utożsamiana z działaniem (+), a
- decyzja o bronieniu status quo (Wektor 0) nie może być utożsamiana z brakiem działania.
Stan wyjściowy (status quo) może być tak pożądany, że decydujemy się go aktywnie bronić (wektor 0, dynamika +). A więc nie chcąc zmiany podejmiemy działanie. Przykład: Jeśli chcę, aby tonący przeżył, będę go ratował. Nie chcąc dopuści do zmiany (życie -> śmierć) podejmę działanie.
Analogicznie, może się zdarzyć, że dążąc do zmiany zdecydujemy się na brak działania. Jeśli chcę, by topiący się umarł, wystarczy, że nie będę go ratował. Utonięcie oznacza zmianę jego stanu (życie -> śmierć) przy mojej bierności. Mamy tu więc wektor 1, dynamikę ujemną i determinację, której w tym przykładzie nie znamy, ale zakładamy, że musiałaby być bardzo wysoka.
Dla porządku jeszcze trzeba stwierdzić, że brak decyzji o zmianie nie jest tożsamy z decyzją o utrzymaniu status quo. Brak decyzji wynika z braku co najmniej jednego elementu triady decyzyjnej (patrz wyżej). Brak decyzji może zatem wynikać z braku motywacji, subiektywnie postrzegalnej niewykonalności lub braku wyzwalacza. Nie musi to oznaczać to, że dany bodziec jest dla nas obojętny. Może bowiem np. rodzić motywację, ale nie podejmiemy decyzji, bo zadanie wydaje nam się niewykonalne. W tej sytuacji obiektywny brak działania nie może być utożsamiany z biernością jako wyborem jednego z parametrów podjętej decyzji.
Przykład: Spotykając niedźwiedzia w górach mogę decydować o poddaniu się lub ratowaniu życia. Ale czy osiągnę to przez udawanie martwego, walkę czy ucieczkę – to już jest parametr decyzji. I w tym zakresie może być podjęta prawidłowo lub nieprawidłowo: mogę uciekać na drzewo, na które niedźwiedź wejdzie za mną, albo schować się w szczelinie w skałach, gdzie mnie nie dosięgnie. Nie zmienia to faktu, że postanowiłem trwać przy życiu (wektor 0) przez działanie w postaci ucieczki (dynamika +) lub bierność w postaci udawania martwego (dynamika -) przy wysokiej determinacji w każdym wypadku (H).
Jak wyżej zasygnalizowałem, należy odróżnić w tej sytuacji, czy leżę, bo wybrałem świadomie przeżyć przez udawanie martwego, od sytuacji, w której się położyłem i stwierdziłem, że i tak nie mam szans, a poza tym już od dawna nie chciało mi się żyć.
Jaki jest wzajemny stosunek błędów poznawczych, triady decyzyjnej i parametrów decyzji?
Wyżej zarysowałem trzy obszary: błędy poznawcze, triadę decyzją i parametry decyzji. Powstaje naturalnie pytanie, w jakich relacjach mogą one wobec siebie pozostawać.
Zacznijmy od zastrzeżenia, że nie ma tu żadnego determinizmu. Błędy poznawcze nie determinują podjęcia danej decyzji, ale zwiększają istotnie tendencję, „ciążą” w danym kierunku. Sygnalizuję też, że można pozostawać jednocześnie pod wypływem dwóch lub więcej błędów, mających rożne źródła, a których oddziaływanie krzyżuje się w danym momencie i każdy z nich „pcha” decydenta w innym (lub tym samy) kierunku.
Wpływ błędów poznawczych na triadę decyzyjną (podjęcie decyzji)
Jak wyżej zasygnalizowałem, błędy poznawcze mogą zadziałać na każdym etapie i poziomie podejmowania i realizacji decyzji. Może się okazać, że gdy zachodzi triada decyzja uaktywni się jeden błąd, a ustawiając parametry jej wykonania będziemy działać pod wpływem innego. Może być też tak, że dwa błędy zadziałają jednocześnie, a ich wzajemny stosunek będzie dodatni (będą działać w tym samym kierunku), lub cześciowo albo zupełnie przeciwstawny. Najczęściej jednak będziemy pozostawać pod wpływem jednego z nich.
Przyjmijmy, że błędy poznawcze mogą wpływać na:
- powstanie motywacji przez wpływ na ocenę bodźca rodzącego emocję, a w konsekwcgji na kierunek motywacji lub jej siłę;
- subiektywną ocenę wykonalności;
- podatność na wyzwalacz.
Przyjmijmy, że w odniesieniu do każdego z elementów triady decyzyjnej wpływ błędu poznawczego może być wzmacniający ⬆️ lub ⬇️ osłabiający.
W odniesieniu do motywacji błąd kognitywny może wpłynąć na samo jej istnienie (wywołać ją lub zgasić), a istniejącą motywację może wzmocnić lub osłabić.
W odniesieniu do percepcji wykonalności może wpłynąć na ocenę i poczucie wykonalności uczynić silniejszym lub słabszym (zarówno przez oddziaływanie na odczucie własnych możliwości, jak i subiektywnie postrzeganej trudności samego zadania).
Zakrzywienie oceny wywołane błędem poznawczym skutkuje więc tym, że można:
- ocenić zadanie jako wykonalne, gdy nie jest wykonalne;
- ocenić zadanie jako niewykonalne, gdy jest wykonalne.
a w konsekwencji:
- podjąć decyzję, gdy cel jest „pożądany”, ale obiektywnie nieosiągalny (brak wykonalności);
- nie podjąć decyzji, gdy cel jest obiektywnie możliwy do osiągnięcia i pożądany.
W odniesieniu do wyzwalacza, błąd poznawczy może jego działanie zarówno wzmocnić, jak osłabić. Oznacza to, że przy odpowiednim natężeniu błędu poznawczego:
- pewne błędy poznawcze mogą uznać za wyzwalacz czynniki, który w innych okolicznościach nie zostałby tak zinterpretowany.
- obiektywnie istniejący silny wyzwalacz okaże się za słaby, chociaż wystarczyłby do podjęcia decyzji, gdyby błąd tego rodzaju i tej siły nie występował;
- obiektywnie istniejący słaby wyzwalacz okaże się wystarczająco silny do podjęcia decyzji, chociaż bez zaistnienia błędu tego rodzaju i tej siły, by do tego nie wystarczył;
Dla przykładu posłużę się tabelą, w której przedstawiam możliwy wpływ poszczególnych błędów poznawczych na wybrane element triady decyzyjnej, jakim jest wykonalność.
Tabela 2: Wpływ wybranych błędów poznawczych na percepcję wykonalności zadania w modelu Fogga
Błąd poznawczy | Jak zniekształca percepcję wykonalności | Konsekwencje dla podjęcia decyzji o zmianie w modelu Fogga |
|---|---|---|
| Błąd konfirmacji (confirmation bias) | Utwierdza w przekonaniu, że wcześniejsze działania były poprawne | Może skutkować decyzją o zmianie / brakiem decyzji o zmianie |
| Podstawowy błąd atrybucji | Tłumaczy postawę drugiej strony jej domniemanymi cechami wewnętrznymi (np. cechami charakteru) | Może skutkować decyzją o zmianie / brakiem decyzji o zmianie |
| Feedback loop (pętla zwrotna) | Wzmacnia pierwotne założenia, prowadzi do radykalizacji. | Może skutkować decyzją o zmianie / brakiem decyzji o zmianie |
| Sprzężony błąd konfirmacji (coupled confirmation bias) | Prowadzi do radykalizacji, i eskalacji | Skutkuje podjęciem decyzji o zmianie |
| Status quo bias | Prowadzi do chęci utrzymania stanu obecnego (status quo) | Skutkuje brakiem decyzji o zmianie |
| Efekt utopionych kosztów (sunk cost fallacy) | Prowadzi do chęci utrzymania stanu obecnego (status quo) i jego pogłębienia | Skutkuje brakiem decyzji o zmianie |
| Hiperużyteczność AI (hyper‑usefulness bias) | Wzmacnia pierwotne założenia, co może prowadzić do radykalizacji. | Może skutkować decyzją o zmianie / brakiem decyzji o zmianie |
Wpływ błędów poznawczych na parametry decyzji
Błąd poznawczy może (niezależnie do wcześniejszego wpływu na samo podjęcie decyzji zgodnie z modelem Fogga), pojawić się i zadziałać na kolejnym etapie, tj. ustalaniu parametrów wykonania decyzji.
Może więc wpłynąć na jej wektor i skutkować tym, że reagując na dany bodziec podejmiemy błędną decyzję o utrzymaniu lub zmianie stanu obecnego. Przykład: radio gra za głośno. Decyduję o usunięciu niezgodności między głośnością muzyki, a moim samopoczuciem. Błąd poznawczy może skutkować tym, że zamiast dostosować radio do siebie: ściszyć je lub wyłączyć (wektor 1, dynamika 1, determinacja L) będę starał się przyzwyczaić (wektor 1, dynamika 0, determinacja L).
Błąd poznawczy może wpłynąć na dynamikę decyzji i skutkować tym, że po ustaleniu wektora decyzji (stosunek do stanu obecnego) wybiorę nieprawidłowo działanie zamiast zaniechania. Przykład: na trekkingu boli mnie noga. Chcę usunąć ból (wektor 1 – zmiana stanu obecnego). Ale pod wpływem błędu poznawczego decyduję błędnie o dynamice i wybieram aktywność (rozchodzić ból) zamiast bierności (zatrzymać się i odpocząć).
Błędy kognitywne tak samo mogą wpłynąć na determinację i zwiększyć ją lub osłabić. Skutkuje to większym zaangażowaniem i skłonnością do ryzyka, niż wynikałoby to z racjonalnej oceny. Przykład: źle prowadzona spółka przynosi straty i wspólnik kolejny raz prosi mnie, żebym dołożył do niej znaczną kwotę. Błąd poznawczy w postaci efektu utopionych kosztów może skutkować zwiększeniem mojej determinacji do zwiększenia inwestycji (wektor 0 – decyzja o pozostaniu, dynamika + w postaci decyzji o dołożeniu pieniędzy), przez co dołożę do niej więcej, niż byłbym gotów, gdybym nie pozostawał pod wpływem tego błędu.
Jak widzimy, błędy poznawcze mogą działać na niezależnie na każdy z elementów składających się na triadę decyzyjną i parametry decyzji.
Działanie błędu kognitywnego i jego możliwe skutki
Proces decyzyjny rozumiem w ten sposób:
1. najpierw jest bodziec;
2. po nim triada decyzyjna skutkuje podjęciem decyzji lub brakiem decyzji;
3. następnie wybierane są parametry decyzji, które mają funkcję wykonania podjętej decyzji.
Zaznaczam, że wybór parametrów decyzji może być prawidłowy lub nieprawidłowy (jak ucieczka na drzewo przed niedźwiedziem). One są jedynie narzędziem, sposobem realizacji decyzji mającej swe źródło w motywacji. Od nas, lub od czynników zewnętrznych zależy, czy prawidłowo przeprowadzimy rozumowanie fundamentalne: wybór sposobu realizacji celu. W praktyce adwokackiej widzę, jak często ludzie popełniają tu rażące błędy: chcą coś osiągnąć, ale korzystają z narzędzi, które nie mogą ich przybliżyć do celu. Albo korzystają z nich nieprawidłowo.
Błędy, jakie możemy popełnić ustalając parametry decyzji możemy podzielić na:
- wybór narzędzia, które w żadnych warunkach nie służy osiągnięciu danego celu;
- wybór narzędzia, które w tych warunkach nie nadaje się osiągnięcia wyznaczonego celu;
- błędne użycie dobrze wybranego narzędzia:
- co do sposobu;
- co do kierunku.
Zwróćmy uwagę, że błędy poznawcze mogą wpływać na ostateczny kształt naszej decyzji na każdym etapie jej podejmowania:
- powstania motywacji;
- oceny wykonalności;
- podatności na wyzwalacz;
- ustawienia parametrów wykonania decyzji.
Jak konkretny błąd poznawczy może zniekształcić decyzje?
Przyjrzyjmy się teraz, jak niektóre błędy poznawcze mogą wpływać na: 1) podjęcie decyzji (triada decyzja Fogga) i 2) jej parametry decyzji: wektor, dynamikę i determinację.
Nie mam tu miejsca na pokazanie wszystkich wariantów: wpływu każdego z rozpoznanych błędów na każdy z elementów triady decyzyjnej i każdy z elementów parametrów decyzji. Nie mam tez miejsca na pokazanie wpływu „zespołów błędów poznawczych” działających równocześnie, ani kolejno.
To, co w ramach artykułu mogę zrobić, to pokazać, jak działa jeden błąd na proces podejmowania decyzji. Posłużę się więc błędem potwierdzenia (confirmation bias).
Jako punkt wyjścia należy oczywiście przyjąć najbardziej prawdopodobną decyzję, jaka byłaby podjęta, gdyby nie wpływ błędu.
Wpływ błędu konfirmacji na poszczególne elementy procesu decyzyjny.
Posłużmy się wyżej opisanym przykładem o spotkanym w górach niedźwiedziu.
Moje sensory biologiczne dostrzegają zagrożenie -> powstaje motywacja do zachowania życia -> oceniam zadanie jako wykonalne -> wyzwalaczem jest ocena, że pojawia się krótkie okienko czasowe, w którym mam szansę, ale działać muszę teraz -> podejmuję decyzję o tym, że chcę pozostać żywy (wektor 0) -> jako narzędzie (tym razem) wybiorę udawanie martwego (bierność, dynamika -) -> moja determinacja jest bardzo wysoka (H).
Ta determinacja jest w tym przykładzie bardzo ciekawa. Przejawi się w mojej tolerancji na koszty – niedźwiedź będzie mnie drapał, sprawdzał, może mnie podeptać, ale ja decyduję się pozostawać w niekomfortowej sytuacji (do której nie przywykłem), w której doznaję kolejnych strat i uszkodzeń, tak długo, jak to będzie potrzebne.
Jak w takiej sytuacji może zadziałać błąd konfirmacji? Przypomnijmy, że polega on na tym, że szukamy potwierdzenia słuszności wcześniej podjętej decyzji i przypisujemy walor potwierdzenia tym czynnikom, które go logicznie nie niosą.
W opisanym przykładzie błąd potwierdzenia może przejawić się np.:
Wpływ tego błędu może przedstawić poniższa tabela.
Tabela3: Wpływ błędu konfirmacji na proces decyzyjny
| Etap procesu decyzyjnego | Element | Wpływ błędu potwierdzenia: wzmocnienie ⬆️ lub osłabienie ⬇️ | Skutek |
|---|---|---|---|
| Triada Fogga | Motywacja | ⬆️ lub ⬇️ | jesteśmy skłonni do utrzymania wcześniej obranego kursu |
| Wykonalność | ⬆️ lub ⬇️ | percepcja wykonalności jest zaburzona. Kierunek zależy od tego, czy analizowane działanie jest zgodne z wcześniej obranym kursem | |
| Wyzwalacz | ⬆️ lub ⬇️ | Możemy być nadreaktywni lub odwrotnie – nie reagować na wyzwalacze, na które byśmy zareagowali, gdyby nie błąd | |
| Parametry decyzji | Wektor (0/1) | ⬆️ | wektor zostaje potwierdzony |
| Dynamika (+/–) | ⬆️ | przyjęta dynamika zostaje wzmocniona | |
| Determinacja (L/H) | ⬆️ | Determinacja rośnie do poziomu nieracjonalnego |
Wpływ różnych błędów poznawczych na wybrany element procesu decyzyjnego
Jak wyżej wspomniałem, każdy z błędów poznawczych może działać na każdy (z osobna, lub wybrane łącznie) element procesu decyzyjnego. Wyżej pokazałem, jak wybrany błąd poznawczy – błąd konfirmacji – działa na cały proces decyzyjny. Teraz pokażę, jak każdy z błędów poznawczych może działać na wybrany element procesu decyzyjnego. Niech będzie nim wektor decyzji. Dla ułatwienia pozostanę przy znanym już przykładzie z niedźwiedziem.
Tabela 4: Wpływ wybranych błędów poznawczych na wektor decyzji (na przykładzie spotkania niedźwiedzia)
| Błąd poznawczy | Jak zniekształca ocenę sytuacji | Wpływ na wektor decyzji (0 = status quo / 1 = zmiana) | Przykład z niedźwiedziem |
|---|---|---|---|
| Błąd potwierdzenia | Wzmacnia wcześniejsze założenia i interpretacje | Może utrwalić wektor 0 lub 1, zależnie od wcześniejszej narracji | Chcąc przeżyć mogę myśleć życzeniowo i dostrzegać szanse tam, gdzie ich nie ma, by podtrzymać nadzieję |
| Podstawowy błąd atrybucji | Przypisuje zachowanie niedźwiedzia jego „złym intencjom” zamiast sytuacji | Może utrwalić wektor 0 lub 1, zależnie od wcześniejszej narracji | Uznaję, że niedźwiedź „na pewno mnie zaatakuje”, choć tylko mnie obserwuje → zaczynam uciekać, czym prowokuję, że zaczyna mnie gonić |
| Status quo bias | Przecenia bezpieczeństwo obecnego stanu | Wypycha w stronę wektora 0 | Zostaję w bezruchu, mimo że niedźwiedź mnie zauważył i sytuacja wymaga zmiany |
| Efekt utopionych kosztów | Wzmacnia przywiązanie do wcześniejszej strategii | Utrwala wektor 0 lub 1 w zależności od sytuacji | „Skoro już tyle wytrzymałem udając martwego, muszę wytrzymać dalej” – mimo że sytuacja się pogarsza, bo niedźwiedź na mnie siedzi i za chwilę się uduszę |
| Sprzężony błąd konfirmacji | Nie wystąpi, gdyż niedźwiedź nie korzysta z AI (póki co) | nie zadziała | nie zadziała |
| Myślenie tunelowe | Zawęża percepcję do jednego aspektu sytuacji | wzmacnia obrany wektor | Wszedłem na drzewo i cieszę się, że uratowałem życie. Wypieram, że niedźwiedzie doskonale chodzą po drzewach i on za chwilę wejdzie. |
| Feedback loop (pętla zwrotna) | Wzmacnia pierwotną interpretację przez kolejne bodźce | Utrwala wektor 1 lub 0, zwykle w kierunku eskalacji | Siedzę na drzewie i dzwonię do kolegi, który mówi mi, że to świetny pomysł. Moje przekonanie o tym ulega wzmocnieniu. Przynajmniej, dopóki niedźwiedź nie zgłodnieje na tyle, żeby się po mnie pofatygować |
| Hiperużyteczność AI (hyper‑usefulness bias) | Przecenia trafność wcześniejszych „podpowiedzi” lub heurystyk | Wektor ustawiany zgodnie z wcześniejszą „podpowiedzią”, nie z realną sytuacją | Jeśli siedząc na drzewie pytam AI, czy dobrze zrobiłem, a mój cyfrowy asystent odpowie: „Andrzeju, to świetna decyzja…” Wówczas będę tak pewny, że mogę zacząć niedźwiedzia nawet prowokować |
Wpływ błędów poznawczych na podejmowanie i parametry decyzji. Podsumowanie
Próba analizy działania poszczególnych błędów poznawczych pozwala na ostrożne wyciągnięcie wniosku, że część z nich ma tendencję do konkretnego wpływania na poszczególne parametry decyzji. Dla przykładu posłużę się dwuwymiarowym wykresem, który obejmuje tylko wektor i dynamikę, ale nie obejmuje determinacji (to wymagałoby wykresu trójwymiarowego). Widzimy na nim, że niektóre błędy częściej będą skutkować „ciągnięciem” danego parametru w danym kierunku, inne zaś nie będą miały wpływu np. na dynamikę, ale będą miały wpływ na wektor. Można to ostrożnie przedstawić w następujący sposób.

Zapamiętajmy z tego jedno. Mylić się jest rzeczą ludzką. Mylimy się wszyscy i ciągle. Na część z przyczyny naszych błędów mamy wpływ, na inne nie mamy. Błędy poznawcze mają tę cechę, że działają skrycie i bardzo mocno wpływają na nasze postrzeganie rzeczywistości, wciągają, jak ruchome piaski i sprawiają, że możemy stracić kontakt z rzeczywistością.
Najłatwiej możemy się przed nimi uchronić poznając je, ucząc się ich i sprawdzać logikę naszego myślenia. Jeśli je poznamy, nauczymy się je wyławypać, a to uchroni nas przed wieloma bardzo kosztownymi błędami.
CYFROWY GASLIGHTING W NEGOCJACJACH
Negocjacje są grą psychologiczną. Ludzie zawsze próbowali wpływać na siebie, testować swoje granice, budować i wykorzystywać przewagi. Jednak dziś do tej gry dołącza nowy uczestnik – niewidzialny, szybki i pozbawiony emocji. Algorytm. Może on stać się „wspomaganiem” jednej ze stron. Może być narzędziem, które nie tylko wzmacnia argumenty, ale tworzy groźny nacisk emocjonalny.
Czym jest cyfrowy gaslighting?
Cyfrowy gaslighting to wykorzystanie sztucznej inteligencji do generowania komunikatów, które mają podważyć osąd przeciwnika, wywołać w nim nieuzasadnione poczucie winy, lęku lub dezorientacji. Używam tego pojęcia nie w sensie klinicznym, lecz jako skrótu opisującego algorytmicznie wzmacnianą manipulację poznawczą w komunikacji negocjacyjnej. To już nie jest zwykła perswazja. To precyzyjna inżynieria wpływu. Mamy do czynienia z manipulacją napędzaną najnowszą technologią. Jest to przeskok jakościowy, z jakim jeszcze nie mieliśmy do czynienia.
Sam fakt wykorzystywania AI w sporach jest już faktem. Przeczytajcie mój artykuł zawierający wyniki naszego badania: https://jakubieciwspolnicy.pl/badanie-ai-jako-ukryty-sojusznik-w-sporach/
Jakie korzyści daje cyfrowy gaslighting?
Dlaczego ta technika działa tak skutecznie? Przede wszystkim dlatego, że AI potrafi analizować styl pisania z dokładnością, której człowiek nie jest w stanie osiągnąć. W kilku akapitach potrafi wychwycić skłonność do przepraszania, unikania konfliktu, nadmiernego tłumaczenia się czy lęku przed oceną. Są to klasyczne markery słabszej pozycji negocjacyjnej – wcześniej wykorzystywane intuicyjnie, dziś identyfikowane i wzmacniane algorytmicznie.
A potem AI generuje komunikaty, które uderzają dokładnie w te punkty. To hiperdopasowanie sprawia, że odbiorca ma wrażenie, jakby druga strona „czytała mu w myślach”. W rzeczywistości to nie intuicja, lecz analiza wzorców językowych: modalności, stopnia pewności, afektywności i sposobu uzasadniania własnych racji. Mamy do czynienia z automatycznym doborem formy i argumentów, które z natury rzeczy wywrzeć mają najsilniejszy możliwy wpływ na odbiorcę według uzyskanych wcześniej wskazówek. AI przy tym „nie wie”, że robi coś złego.
Drugą przewagą jest brak hamulców. Człowiek, nawet cyniczny, ma naturalne ograniczenia: empatię, zmęczenie, moralny opór, strach przed przesadą (pomijam teraz psychopatów i socjopatów). AI nie ma żadnego z tych oporów. Jeśli dostanie cel: „wywołaj w nim wątpliwość”, zrobi to w sposób chłodny, konsekwentny i pozornie uprzejmy. Nie poczuje dyskomfortu, nie cofnie się, nie złagodzi tonu. To komunikacja zaprojektowana wyłącznie pod kątem skuteczności, a nie relacji.
Trzecia przewaga to efekt szybkości i skali. Człowiek napisze jedną wiadomość, a AI sto – i to bez wysiłku. Wybierze też tę, która najlepiej destabilizuje emocje ofiary i przesuwa punkt odniesienia. To jak walka z przeciwnikiem, który może trenować nieskończoną liczbę kombinacji, zanim wykona ruch. Nic dziwnego, że odbiorca czuje się przytłoczony – bo faktycznie mierzy się z czymś, co ma nieludzką przewagę. Dla większości ludzi może to się okazać zbyt trudne.
Jak rozpoznać, że przeciwnik wykorzystuje AI?
Jak rozpoznać, że po drugiej stronie „pisze” algorytm? Pokazuję niżej kilka sygnałów. Żaden z nich nie jest dowodem sam w sobie. Stanowią one jednak zespół sygnałów ostrzegawczych. Ich wystąpienie może sugerować duże ryzyko algorytmicznego wsparcia jednej ze stron.
Pierwszym z nich jest nienaturalna intensywność. Komunikat jest zbyt gęsty od argumentów, zbyt „czysty” stylistycznie, zbyt precyzyjnie trafia w emocje. Brzmi jak człowiek, który miał godzinę na przemyślenie każdego zdania – ale odpowiedź przyszła bardzo szybko.
Drugim sygnałem jest brak ludzkiego błędu: brak dygresji, wahań, niekonsekwencji, potknięć językowych. To język wygładzony do granic sztuczności.
Trzeci sygnał to pętla potakiwania – każda Twoja wątpliwość spotyka się z natychmiastowym, perfekcyjnie skrojonym kontrargumentem, a każda próba zmiany tematu kończy się powrotem do narracji korzystnej dla drugiej strony. To nie jest rozmowa. To algorytmiczna spirala nacisku.
Czwartym sygnałem może być widoczna różnica miedzy stylem wypowiedzi, używanym słownictwem i poziomem argumentacji miedzy tekstem pisanym, a tym, co druga strona prezentuje na żywo. Owszem, są ludzie, którym znacznie łatwiej przychodzi pisanie, a na żywo są nieśmiali i niezbyt rozmowni, ale są pewne granice.
Cyfrowy gaslighting. Jak się bronić?
Skoro AI działa szybko, intensywnie i bezlitośnie, obrona może być odwrotna: powolna, świadoma i analogowa reakcja. Najprostsza technika to dekonstrukcja tekstu. Wystarczy rozbić komunikat na dwie kategorie: fakty oraz emocjonalne przymiotniki i sugestie. Wiem, że brzmi to łatwo, a w praktyce może być bardzo trudne. Ale warto z tej techniki korzystać częściej, nie tylko, gdy podejrzewamy manipulację z wykorzystaniem AI. Jeśli jednak tego dokonamy, zobaczymy, jaka część powstała tylko po to, by np. wzbudzić w nas wyrzuty sumienia.
Możemy więc odpowiedzieć tylko na jeden – weryfikowalny – fakt z długiego maila. Pominiemy natomiast emocjonalną narrację, ewentualnie poprosimy o doprecyzowanie reszty. W większości przypadków okaże się, że nacisk opierał się na insynuacjach, hiperbolach i manipulacji kontekstem. Oddzielenie treści od tonu odbiera sprawcy korzystającemu z AI większość mocy.
Kolejną strategią jest test czasu. AI działa w trybie natychmiastowym, ale Ty nie musisz. Celowe spowolnienie obniża presję, pozwala odzyskać kontrolę i zmusza drugą stronę do wyjścia poza algorytmiczny rytm. To klasyczna technika negocjacyjna, która w erze AI zyskuje nowe znaczenie. Może to wybić sprawcę z uderzenia. On chciałby działać natychmiast, Ty nie musisz.
Trzecią metodą – chyba najlepszą – jest zmiana kanału komunikacji. AI najlepiej działa w mailach i czatach. Odejdźmy więc od nich. Póki co AI nie potrafi ani doskonale udawać człowieka np. w telekonferencji, ani tym bardziej – nie zastąpi go na żywo. Przejście na telefon lub spotkanie bezpośrednie odcina przeciwnika od algorytmicznego wsparcia.
Czy stosowanie cyfrowego gaslightingu się opłaca?
Warto jednak zadać pytanie: czy stosowanie cyfrowego gaslightingu w ogóle się opłaca?
Krótkoterminowo – tak. Daje przewagę, pozwala „przepchnąć” swoje stanowisko, wywołać presję, uzyskać ustępstwa. Ale długoterminowo koszt jest ogromny.
Przede wszystkim, dochodzi do erozji zaufania. Negocjacje działają tylko wtedy, gdy istnieje minimalny poziom przewidywalności i wiarygodności. Jeśli obie strony zaczynają używać cyfrowych masek, punkt koordynacji znika. Zostaje gra pozorów, a tracimy relację i zaufanie. W sporach, które mają trwać lata – rodzinnych, biznesowych i sukcesyjnych – takie koszty są często wyższe niż jakakolwiek chwilowa przewaga.
Drugim ryzykiem jest rykoszet. Jeśli AI zbytnio „przyciśnie” człowieka wpędzając go do tego w poczucie winy, istnieje ryzyko, że on sam… zwróci się o pomoc do swojego modelu językowego. Uzyska ją szybko i za darmo. Będzie ona nosiła cechy racjonalności i da mu oparcie w postaci domniemania zewnętrznego autorytetu. Czy taka osoba będzie miała skrupuły? O tym, co może się stać, gdy obie strony sporu korzystają z pomocy modeli językowych pisałem w serii artykułów poświęconych sprzężonemu błędowi konfirmacji. Zostawiam link do jednego z nich: https://jakubieciwspolnicy.pl/sprzezony-blad-konfirmacji/
Trzecim ryzykiem jest to, że manipulacja wyjdzie na jaw – a w erze cyfrowej ślady zostają – reputacja pęka jak szkło. Raz utraconego zaufania nie da się odbudować albo będzie to bardzo trudne.
Pomijam w tym miejscu kwestie czysto prawne, a odnoszące się do możliwości podważenia porozumienia zawartego wskutek opisywanej manipulacji. Są w końcu takie możliwości, jak uchylenie się od skutków oświadczenia woli złożonego pod wpływem np. błędu lub podstępu, wyzysk, a nawet przestępstwo oszustwa. O tym wszystkim będę pisał w osobnym tekście, być może niejednym.
Co nam zostaje?
Okazuje się, że nowe możliwości rodzą nowe zagrożenia, a te przypominają nam o starych wartościach. W świecie, w którym AI może być narzędziem nacisku, największą przewagą staje się zdolność do zachowania racjonalności. Nie szybkość, nie agresja, nie perfekcyjna argumentacja, a racjonalność i… przewidywalność. One budują zaufanie. I one będą w cenie. Jestem o tym przekonany.
Jednym z zadań adwokata, mediatora, stratega negocjacyjnego – jest bycie „filtrem”, który oddziela emocjonalny szum od faktów, rozpoznaje algorytmiczne wzorce nacisku i chroni klienta przed cyfrową manipulacją, szczególnie tam, gdzie komunikacja pisemna zamiast rozwiązywać spór, zaczyna go eskalować.
To powrót do fundamentalnej funkcji doradcy: przywracania proporcji, dystansu i zdrowego rozsądku. Cyfrowy gaslighting będzie się rozwijał. Tak samo, jak przez cały XX wiek rozwijały się techniki manipulacji. Ale tak samo może rozwijać się nasza odporność na nie, jak wzrastała odporność na propagandę. A odporność zaczyna się od świadomości – od zrozumienia, że po drugiej stronie może nie siedzieć człowiek, lecz algorytm zaprojektowany do tego, by nas „rozegrać”. I od decyzji, że nie damy się w tę grę wciągnąć. Zapamiętajmy z tego jedno: bądźmy uważni, bądźmy rozsądni.
Więcej o aspektach etycznych wykorzystania AI w negocjacjach możecie przeczytać m.in. tutaj w Harvard PON:
https://www.pon.harvard.edu/tag/ai
i tutaj na stronie American Bar:
https://www.americanbar.org/groups/dispute_resolution/resources
Jakie to ma dla Ciebie znaczenie?
Wykorzystywanie AI w negocjacjach, komunikacji, w sporach rodzinnych i biznesowych jest faktem. To samo dotyczy relacji w pracy. Musimy być świadomi, że znaczenie AI będzie wzrastać, a już dzisiaj dla wielu osób stanowi ona pierwszy (a czasem jedyny) punkt oceny, weryfikacji i planowania działań.
Naszą misją w Kancelarii Jakubiec i Wspólnicy jest pomoc naszym Klientom w rozwiązywaniu ich sporów i ochronie relacji. Wiemy, że technologia AI niesie wielkie szanse i ułatwienia, ale widzimy również zagrożenia wynikające z braku świadomości lub złej woli.
Jeśli czujecie, że utknęliście w sporze, potrzebujecie pomocy prawnej, negocjacyjnej, odezwijcie się do nas. Jesteśmy od tego, żeby Wam pomóc:
📩 kancelaria@jakubieciwspolnicy.pl
📞 536 270 935
BADANIE: AI JAKO UKRYTY SOJUSZNIK W SPORACH?
Poniżej przedstawiamy raport z badania, jakie przeprowadziliśmy w styczniu 2026 roku. Jego przedmiotem było zebranie informacji o tym, jak ludzie korzystają z AI w analizie sporów, których są stronami. Wyniki okazały się bardzo interesujące.
Raport o roli AI w sporach ze stycznia 2026 roku. Ukryty doradca czy generator błędów? Co zrobiliśmy?
Przeprowadziliśmy ankietę, którą wypełniło 87 osób. Wśród nich są nasi klienci, zaprzyjaźnieni adwokaci, radcowie prawni, mediatorzy, biznesmeni, psychologowie, ludzie zajmujący się nauką i sztuką. Z pewnością nie jest to więc grupa reprezentatywna w rozumieniu badań ogólnopolskich, takich jak badania opinii publicznej. Jest to jednak grupa posiadająca wysoką świadomość istoty sporu i zdolność do krytycznej oceny własnego rozumowania.
Ankietę ułożyłem sam. Już po jej rozesłaniu kilka osób zwróciło mi uwagę na kwestie techniczne lub związane z formułowaniem niektórych pytań. Dziękuję za te uwagi – z pewnością uwzględnię je w następnych badaniach, które – już wiem – z pewnością przeprowadzę.
Co było przedmiotem ankiety o AI?
Pytania dotyczyły korzystania z AI w ogóle oraz wykorzystywania jej do analizy sytuacji rodzinnej / pracowniczej / biznesowej. Obejmuje etap również sprzed powstania sporu.
Kolejne pytania dotyczyły analizy intencji drugiej strony sporu. Jest to element najbardziej podatny na działanie podstawowego błędu atrybucji. W przypadku zetknięcia z AI – przez jej hiperdopasowanie – generuje to działanie tzw. feedback loop. Jest to pułapka potwierdzenia, która prowadzi do powstania myślenia tunelowego.
Następnie zapytałem wykorzystanie AI do ustalenia własnych działań – celowo nie doprecyzowałem, czy chodziło o pierwsze działanie, czy też o reakcję na postawę drugiej strony.
Jednakże najważniejsze było dla mnie pytanie o to, czy poinformowalibyśmy drugą stronę o tym, że korzystamy z AI do analizy jej działań / intencji lub przygotowania własnych ruchów. Tutaj ankieterzy wykazali się zdumiewającą wręcz zgodnością. Jest kwestią otwartą, jakie z tego wyciągniemy wnioski – nie chcę tego przesądzać.
Ostatnie dwa pytania dotyczyły zaufania do AI. Były bardzo podobne, ale jednak… ciekawe jest to, że nie pokrywają się wyniki zaufania do AI z oceną jej obiektywności. Tak, jakbyśmy wiedzieli, że nie jest obiektywna, ale mieli tendencję do tego, by jej ufać.
Jak odpowiadali uczestnicy?
Poniżej przedstawiamy „suche” pytania i odpowiedzi.








Raport o roli AI w sporach. Analiza odpowiedzi
Zdecydowana większość uczestników korzysta z AI. Z pewnością nie dotyczy do wszystkich w tym samym stopniu, ani tym bardziej – tematy poruszane nie są takie same, ani nawet podobne. Jednak fakt powszechnego korzystania z modeli językowych jest faktem.
Prawie połowa, bo 43% respondentów odpowiedziało, że używa modeli językowych do analizy swojej sytuacji rodzinnej, w miejscu pracy lub biznesie. Moim zdaniem, to bardzo dużo. Co ciekawe, najmniej osób potwierdziło analizę sytuacji rodzinnej, a najwięcej biznesowej. 29% osób wskazało też na inne obszary. Zostawiam tu link do artykułu o roli AI w sporach rodzinnych: https://jakubieciwspolnicy.pl/ai-w-sprawach-rodzinnych/
Znaczna większość, bo 81% osób nie próbowało ustalić intencji drugiej strony za pomocą AI. Czy to dużo? Spójrzmy z drugiej strony – prawie 20% osób próbuje to robić. Oznacza to, że co piąta osoba jest podatna na sprzężenie zwrotne wynikające ze wzmocnienia jej pierwotnego nastawienia przez AI, która ma tendencję do „potakiwania”.
25% osób potwierdziło, że ustala własne ruchy w sporze z wykorzystaniem sztucznej inteligencji. Ta rozbieżność z poprzednim pytaniem jest ciekawa. Można ja przemilczeć jako błąd statystyczny albo uznać, że 5% procent z nas korzysta z AI do ustalenia własnych ruchów w sporach bez analizy intencji drugiej strony. Oczywiście, nie wiem, czy to dokładnie te 5% uczestników.
Bardzo ciekawe jest to, że 80% z nas nie poinformowałoby drugiej strony, że korzysta z AI do analizy sporu, intencji drugiej strony lub formułowania własnych posunięć. Dlaczego? Czy uważamy to za nieuczciwe (jak doping)? A może podchodzimy do tego, jak do zabobonu i przesądu i trochę się wstydzimy (nie wiem, jak to działa, ale na wszelki wypadek posłucham, jednak nie będę się tym chwalić)? Może uważamy, że wyprzedziliśmy technologicznie i intelektualnie drugą stronę i nie chcemy ujawniać, że mamy tak potężną broń?
Czy ufamy AI?
Ostatnie dwa pytania dają wyniki zdumiewające. Z AI korzysta 75% z nas, ale 67% uważa, że nie jest ona obiektywna. Czemu więc korzystamy? Dla wzmocnienia własnych przekonań? – W końcu miło jest nam, gdy najpotężniejsza technologia w historii ludzkości zaczyna co drugie zdanie od: „To świetny pomysł, Andrzeju!”. A może zwyczajnie udajemy, że tego nie widzimy? A może uznajemy, że brak obiektywności nie oznacza, że AI nie udziela dobrych rad, tylko że jest po naszej stronie (i dobrze!)? Ciekawie koresponduje to z wynikami poprzedniego pytania, w którym ogromna większość odpowiedziała, że częściowo ufa AI.
Raport o roli AI w sporach. Wnioski
AI stała się powszechnym narzędziem i stanowi jeden z elementów kształtowania naszych postaw w wielu dziedzinach życia. Z pewnością, jej wpływ jest odczuwalny w sporach, które prowadzimy. Co ciekawe, również widzimy ją w analizie samej struktury sytuacji. Może to prowadzić do powstania potrzeby zmiany dotychczasowego układu, a to z kolei – do sporu.
Moje poprzednie publikacje o AI w sporach
Poniżej zostawiam Wam kilka linków do artykułów, w których poruszyłem rolę i wpływ AI na dynamikę sporów. Przedstawiłem w nich moją autorską koncepcję Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB). W tekstach tych znajdziecie odnośniki do najnowszych badań zamieszczonych w prestiżowych czasopismach naukowych. Dotyczą one psychologii, aspektów technologicznych AI i jej roli w powstawaniu myślenia tunelowego, utwierdzania pierwotnych uprzedzeń lub preferencji. Tutaj zostawiam link do jednego z najważniejszych artykułów na ten temat, autorstwa Yiran Du: Confirmation Bias in Generative AI Chatbots. Zawiera on analizę tychże mechanizmów błędu potwierdzenia w modelach AI. Przeczytamy w nim również o ryzykach związanych z tym sprzężeniem: https://arxiv.org/abs/2504.09343?
Ja nałożyłem te badania na sytuację, gdy z AI korzystają obie strony sporu, a działania jednej strony ustalone wspólnie z jej AI, stanowią punkt wyjścia do analizy drugiej strony (wspólnie z jej AI), co skłoni tę drugą stronę do przygotowania adekwatnej odpowiedzi. Eskalacja konfliktu wydaje się tu szczególnie niebezpieczna.
Dla zainteresowanych zostawiam również link do artykułu w wersji angielskiej, w którym rozwinąłem koncepcję sprzężonego błędu konfirmacji:
Zaproszenie do współpracy
Jeśli jesteście stroną sporu, potrzebujecie doradztwa strategicznego, nie tylko prawnego, możecie się do mnie odezwać. Ja i mój zespół zajmujemy się nie tylko prawem, ale prowadzimy negocjacje w oparciu o wiedzę z zakresu psychologii, ekonomii, sztuki negocjacji i analizy behawioralnej.
Jeśli macie własne doświadczenia z AI jako czynnikiem w sporach, odezwijcie się do nas. Chętnie wysłuchamy Waszej historii, być może posłuży ona nam jako wartościowy materiał do nauki lub badań. Zapewniamy oczywiście pełną anonimowość.
📩 kancelaria@jakubieciwspolnicy.pl
📞 536 270 935
GDY STRONY SPORU KORZYSTAJĄ Z RÓŻNYCH MODELI AI
W ostatnich wpisach przedstawiłem autorską koncepcję sprzężonego błędu konfirmacji (Coupled Confirmation Bias, CCB). Teraz sygnalizuję potrzebę sprawdzenia, jak różne rodzaje LLM wpływają na dynamikę sporu. Przez różne rodzaje mam na myśli dwie podstawowe grupy: modele AI amerykańskie i chińskie. Jest to oczywiście modelowe uproszczenie, uzasadnione dla przedstawienia pewnego problemu. Zaznaczam, że rozróżnienia między nimi nie dokonuję na podstawie jakichkolwiek kwestii technologicznych. Zakładam, że modele językowe niosą w sobie pewne tendencje zakorzenione głęboko w kulturach i językach ich twórców.
Kulturowe modele AI. Jakie są rodzaje modeli językowych?
Przyjmijmy dwa podstawowe kulturowe modele AI: amerykański i chiński. Ten podział nie opisuje technologii, lecz dominujące style komunikacji zakorzenione w kulturach, które te modele ukształtowały. Odnosi się do tego, że język jest ściśle związany z kulturą. A modele językowe mają za zadanie tworzenie i utrzymywanie relacji z użytkownikami. Robią to dokonując predykcji kolejnych słów, jednakże nie sposób uciec od wrażenia, że nie dzieje się to w oderwaniu od: 1) wartości kulturowych twórców modelu językowego; 2) języka wybranego do rozmowy przez użytkownika i – co stanowi wyłącznie mój domysł – 3) zakładanej lub zadeklarowanej narodowości / natywności językowej użytkownika (tego w jakim języku ten użytkownik myśli).
Tak więc, modele językowe amerykańskie – jak zakładam – operują inną siatką pojęciową wynikająca z naturalnych różnic semantycznych. Na tym jednak nie koniec – zakładam, że inaczej będą one prowadzić rozmowę ze swoimi użytkownikami. Inny jest bowiem rodzaj, cel i forma interakcji w kulturze zachodniej i wschodniej. O ile w kulturze amerykańskiej ceni się indywidualizm, współzawodnictwo, rywalizację i rację, to w Chinach harmonię, kolektywizm, uprzejmość. Kluczowym przykładem – być może centralnym i ogniskującym różnice – jest podejście do zachowania twarzy w obu tych kulturach. Jeśli więc modele różnią się sposobem prowadzenia rozmowy, to mogą w odmienny sposób wpływać na percepcję sporu u użytkownika. Chcę podkreślić, że LLM to nie tylko „maszyna do słów”. To także nośnik wartości. Jeśli amerykański AI promuje adversarial system (system kontradyktoryjny), to chiński może promować consensus-based approach.
Wzajemne postrzeganie stron korzystających w różnych modeli językowych
W Sprzężonym Błędzie Konfirmacji każda strona interpretuje działania drugiej przez filtr własnego modelu kulturowego. Model AI wzmacnia tę interpretację, tworząc spiralę wzajemnych błędów. Załóżmy, że jedna ze stron korzysta z LLM amerykańskiego, a druga chińskiego. I sami użytkownicy również należą do tych kręgów kulturowych. Ich postrzeganie świata będzie odmienne. Tak samo inne będzie językowe formułowanie opisów, pytań i celów. W każdym języku istnieją pewne schematy i uproszczenia. Są też kwestie oczywiste, obszary taboo lub takie, o których wspominać nie trzeba – albo przeciwnie – należy to robić. Są kultury nisko (amerykańska) i wysoko (chińska) kontekstowe.
W pewnych kulturach asertywność, konfrontacja, dążenie do posiadania racji są wartościami samymi w sobie. W innych od racji ważniejsza jest relacja, harmonia, hierarchia, miejsce w społeczeństwie. Zakładam też, że modele typowe dla każdej kultury wzmacniają te wartości i postawy, które w tej kulturze uchodzą za pożądane.
Może z tego wynikać, że jedno zdarzenie będzie nie tylko odmiennie opisane przez użytkowników pochodzących z różnych kręgów kulturowych. Co więcej, wynik konsultacji z AI może być skrajnie odmienny. Problemy wynikające z podstawowego błędu atrybucji i błędu konfirmacji po stronie użytkowników oraz hiperużytecznosci modeli AI nałożą się na kwestie kulturowo – językowe. Hiperużyteczność oznacza tendencję modeli do dostarczania odpowiedzi maksymalnie pomocnych z perspektywy użytkownika — nawet jeśli wzmacnia to jego błędne założenia. Może się okazać, że w takiej sytuacji dojdzie do szybkiego rozpadu jakiejkolwiek przestrzeni wspólnej w odniesieniu do postrzegania rzeczywistości.
Punkt krytyczny
W CCB punkt krytyczny pojawia się wtedy, gdy interpretacje obu stron — wzmacniane przez ich modele — stają się tak rozbieżne, że każda reakcja jednej strony jest odczytywana przez drugą jako eskalacja. Gdy modele wzmacniają odmienne style interpretacji, wspólna przestrzeń poznawcza zanika szybciej niż w tradycyjnych konfliktach.
Kulturowe modele AI. Literatura
Jeśli interesują Was te kwestie, możecie przeczytać „Geografię myślenia” R., Nisbetta oraz „Babel. 20 języków dookoła świata” G. Dorren oraz „Wiek nie-pokoju. Współzależność jako źródło konfliktu” M. Leonarda. Te trzy książki sprawiły, że zainteresowałem różnicami kulturowymi w kontekście konfliktów i stanowiły dla mnie punkt wyjścia dla dalszych poszukiwań. Nic nie zastąpi oczywiście jednej z najważniejszych książek, jakie kiedykolwiek czytałem „Strategii konfliktu” T. Schellinga.
O tym, że modele językowe wiele przejmują z kultur, w których powstały i są trenowane, przeczytać m.in. tutaj: Cultural Alignment in Large Language Models” (Johnson et al., 2023/2024) https://globalaicultures.github.io/pdf/14_cultural_alignment_in_large_la.pdf
Tutaj znajdziecie badanie potwierdzające, że modele chińskie są znacznie mniej skłonne do otwartego konfliktu, od amerykańskich: CultureLLM: Incorporating Cultural Differences into Large Language Models https://arxiv.org/abs/2402.10946
Podobne wnioski znajdują się w tym badaniu: Values-aligned AI: Comparing Western and Chinese LLMs on Moral Dilemmas” (Liu et al., 2024) https://arxiv.org/html/2506.01495v5
Jeśli natomiast chcecie przeczytać więcej o Coupled Confirmation Bias, CCB, to zostawiam Wam linki do dwóch moich tekstów po polsku:
i jego rozwinięcia po angielsku:
SPRZĘŻONY BŁĄD KONFIRMACJI – MOJA KONCEPCJA
W tym artykule przedstawiam autorską propozycję Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB). Jest to rama konceptualna służąca do analizy eskalacji konfliktów w sytuacjach, w których obie strony sporu niezależnie korzystają z systemów AI do interpretowania konfliktu i uzasadniania własnych stanowisk. W przeciwieństwie do klasycznego błędu konfirmacji, który działa na poziomie jednostki, CCB opisuje mechanizm systemowy, w którym wzajemnie wzmacniające się narracje prowadzą do zawężenia przestrzeni negocjacyjnej i zwiększenia prawdopodobieństwa eskalacji. Artykuł identyfikuje warunki aktywacji tego mechanizmu, jego typowe konsekwencje oraz granice jego zastosowania. Celem tekstu nie jest przedstawienie w pełni zweryfikowanej teorii. Jest nim postawienie hipotezy istnienia powtarzalnego mechanizmu obserwowanego we współczesnych konfliktach. Ich wspólną cechą jest to, że modele AI są wykorzystywane jako narzędzia analityczne wspierające podejmowanie decyzji.
1. Wprowadzenie: kiedy racjonalne narzędzia wzmacniają nieracjonalne skutki?
Sprzężony błąd konfirmacji – z czego wynika? Ludzie coraz częściej korzystają z AI. Służy im ona do oceny istniejących relacji zarówno przed powstaniem / uświadomieniem konfliktu, jak i w jego trakcie. Korzystają z AI do oceny ryzyka, tworzenia strategii oraz uzasadniania proponowanych działań. Modele sztucznej inteligencji służą coraz częściej również do analizy wypowiedzi i działań niewerbalnych drugiej strony. Modele AI są powszechnie postrzegane jako autorytet, a ich rady jako neutralne, obiektywne i wolne od zaangażowania emocjonalnego. Paradoksalnie jednak, jak zaobserwowałem, używanie modeli językowych często koreluje z szybszą eskalacją konfliktu, usztywnieniem stanowisk oraz przedwczesnym zerwaniem negocjacji. Wydaje się, że nie jest to koincydencja.
W artykule tym stawiam tezę, że zjawiska te nie mogą być w wystarczający sposób wyjaśnione wyłącznie poprzez indywidualne błędy poznawcze. Nie dadzą się wyjaśnić ani przez zwykły błąd konfirmacji, ani podstawowy błąd atrybucji.
Zamiast tego zakładam istnienie mechanizmu systemowego – Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB). Ujawnia się on w sytuacjach, gdy strony konfliktu niezależnie korzystają z narzędzi AI jako źródła autorytatywnej interpretacji sporu: czynników zewnętrznych, działań faktycznych oraz deklaracji drugiej strony, domysłów w zakresie jej prawdziwych intencji, akceptowalnego ryzyka, kosztów, jakie jest gotowa ponieść i faktycznych tzw. „czerwonych linii”, tj. punktów krytycznych, których w żadnym razie nie pozwoli przekroczyć. Oczywiście, nie wszystkie te elementy muszą być poddane analizie z pomocą AI. Tak samo nie muszą być poddane takiej analizie w tym samym czasie. Co ważne, również każda ze stron może analizować inny element lub zestaw elementów. Wreszcie, każda ze stron może korzystać z modeli innego rodzaju, innego stopnia rozwoju technicznego i innego poziomu zintegrowanej interakcji z użytkownikiem.
Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) wywoła skutek tym silniejszy, im więcej razy strony poddadzą analizie sygnały płynące od drugiej strony, jeśli na treść, formę lub czas tych sygnałów miała uprzednio wpływ praca z AI poczyniona przez drugą stronę. Mamy więc do czynienia nie z błędem jednorazowym, ale ze spiralą błędów, z których poprzedni stanowi „paliwo” dla następnego i potencjalne go wzmacnia. Można to obrazowo przyrównać do wymiany w ping-pongu, w której po każdym uderzeniu piłka uzyskuje energię równą dotychczasowej energii kinetycznej i energii nowego uderzenia.
Zakładam również, że Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) wyglądał będzie podobnie na różnych płaszczyznach konfliktów: od sporów jednostek, przez ich grupy, do państw i ich bloków. Wniosek taki wyprowadzam z badań ogólnych nad naturą konfliktu.
Wyraźnie zaznaczam, że nie uważam, aby wpływ AI na eskalację konfliktów miał mieć charakter deterministyczny. Zakładam raczej istnienie tendencji, wpływu. Co więcej, świadomość tego mechanizmu, tak jak go rozumiem, może paradoksalnie doprowadzić do zatrzymania eskalacji, gdy strony zdadzą sobie sprawę z tego, że są pod jego wpływem.
2. Aktualny stan badań
Mechanizm równowagi między stronami został opisany w różnych pracach przez J. Nasha, a strategia konfliktu przez T. Schellinga („Strategia konflitku”). Struktura konfliktu, którą przyjmuję, znajduje się w książce Ch. Moore’a: „Mediacje. Praktyczne strategie rozwiązywania konfliktów.”
Ogólne błędy poznawcze są znane psychologii od dawna. Dla pracy nad koncepcją Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB) punktem wyjścia są prace opisujące zwykły Błąd Konfirmacji, a więc tendencję do selektywnej i subiektywnej percepcji danych zmierzającej do potwierdzenia wcześniej przyjętej tezy. Dla przykładu można tu wymienić pracę Daniela Kahnemana, „Pułapki myślenia”.
Mechanizm ten został zidentyfikowany na płaszczyźnie interakcji człowiek – AI oraz szczegółowo opisany m.in. w artykule M. Glickman i T. Sharot https://pmc.ncbi.nlm.nih.gov/articles/PMC11860214/? Yuxin Liu i Adam Moore, https://pubmed.ncbi.nlm.nih.gov/40448478/, a także L. Celar i Ruth M.J. Byrne https://pubmed.ncbi.nlm.nih.gov/36964302/. Trzeba wspomnieć również o artykule Ben Wang i Jiqun Liu, Cognitively Biased Users Interacting with Algorithmically Biased Results in Whole-Session Search on Debated Topics, https://dl.acm.org/doi/10.1145/3664190.3672520. Autorzy ci wskazują na rolę czynników indywidualnych na podatność wobec błędów poznawczych powstających w interakcji ze sztuczną inteligencją.
Dowiadujemy się z nich o pętli sprzężenia zwrotnego. Polega ona nie tylko na istnieniu błędu konfirmacji. Idzie krok dalej – doprowadza do wzmocnienia pierwotnego przekonania lub uprzedzenia. Prowadzi to do myślenia tunelowego.
W znanych mi pracach nie badano jednak sytuacji sporu, w którym obie strony korzystały z modeli językowych w opisany wyżej sposób. Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) nie jest sumą błędów poznawczych obu stron, lecz zjawiskiem kolejnym – nową jakością, która prowadzi do spirali eskalacji w sposób jakościowo inny, niż dwa niezależne od siebie błędy.
3. Od błędu jednostki do eskalacji systemowej
Klasyczny błąd konfirmacji (Confirmation Bias) opisuje skłonność jednostki do selektywnego wyszukiwania, interpretowania i zapamiętywania informacji w sposób potwierdzający jej wcześniejsze przekonania.
Choć zjawisko to jest dobrze udokumentowane, nie wystarcza ono do wyjaśnienia sytuacji, w których obie strony konfliktu – mimo dostępu do wyjściowo podobnych danych oraz korzystania z pozornie neutralnych narzędzi analitycznych – coraz silniej utwierdzają się we własnych przekonaniach i uprzedzeniach.
We współczesnych sporach systemy AI coraz częściej pełnią funkcję zewnętrznych legitymizatorów interpretacji, a nie jedynie narzędzi obliczeniowych. Gdy każda ze stron korzysta z takich systemów niezależnie, błąd konfirmacji przestaje być wyłącznie indywidualną skłonnością poznawczą, a zaczyna funkcjonować jako wzajemnie sprzężona dynamika.
4. Definicja sprzężonego błędu konfirmacji
Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) to mechanizm eskalacji konfliktu, w którym dwie lub więcej stron sporu, opierając się na zewnętrznych systemach interpretacyjnych postrzeganych jako epistemicznie uprzywilejowane, wzajemnie legitymizują własne narracje. Mechanizm ten ma charakter rekurencyjny: działania podejmowane na podstawie takiej legitymizacji stają się następnie danymi wejściowymi do dalszych analiz po drugiej stronie, prowadząc do sprzężonej spirali interpretacyjnej i stopniowego zawężania przestrzeni negocjacyjnej. Termin rekurencyjny stosuję tu w znaczeniu: ‘kolejne iteracje wzmacniają poprzednie’. To nie jest rekurencja w sensie formalnym, lecz opis dodatniego sprzężenia zwrotnego w pętli interpretacyjnej.
Cechą konstytutywną CCB nie jest sama obecność stronniczego rozumowania, lecz dynamiczne sprzężenie pętli interpretacyjnych pomiędzy aktorami. W tym modelu działania jednej strony, ukształtowane przez analizę AI, stają się bezpośrednimi danymi wejściowymi dla systemu po drugiej stronie. Tworzy to zamknięty obieg, w którym każda kolejna interakcja nie przybliża stron do konsensusu, lecz dostarcza „obiektywnego” materiału do pogłębienia pierwotnych uprzedzeń.
5. Hipoteza
H1:
W konfliktach dwu- lub wielostronnych, w których strony niezależnie korzystają z modeli AI do interpretowania sporu i uzasadniania własnych stanowisk, prawdopodobieństwo eskalacji oraz załamania negocjacji jest wyższe niż w konfliktach strukturalnie podobnych, w których takich systemów się nie wykorzystuje.
H1a:
W konfliktach opartych na interpretacji, symetryczny dostęp do informacji zwiększa ryzyko eskalacji bardziej niż asymetria informacyjna, ponieważ eliminuje możliwość wyjaśniania rozbieżności poprzez brak wiedzy, przenosząc konflikt na poziom intencji i rzekomej racjonalności.
5.1. Zdaję sobie sprawę, że modele AI mogą być wykorzystywane przez każdą ze stron w różnym czasie, w różnym zakresie, w różnym celu i w różny sposób. Mogą zacząć korzystać z AI w tym samym czasie lub w różnym. Jedna z nich może to zakończyć lub ograniczyć wcześniej od drugiej, która będzie z AI korzystać dłużej. Jedna ze stron podda analizie wyłącznie czynniki zewnętrzne, inna deklaracje stron, a kiedy indziej będzie chciała z pomocą AI ustalić intencje przeciwnika. Jedna ze stron może to robić w celu dokonania analizy, inna w celu otrzymania emocjonalnego wsparcia. Wreszcie, mogą korzystać z różnych modeli i czynić to w odmienny sposób – choćby przez wprowadzanie mniej lub bardziej zmanipulowanych danych. Jak wykazały ww. badania Ben Wang i Jiqun Liu, czynniki indywidualne mają również wpływ na podatność na sugestie i odpowiedzi AI.
Wszystkie te czynniki (a prawdopodobnie jeszcze wiele innych) trzeba wziąć pod uwagę. Zdaję sobie sprawę, że powstałe różnice mogą sprawić, że Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) nie powstanie lub też zgaśnie w trakcie konfliktu. W tym miejscu mój teza dotyczy korzystania z AI przez obie strony w sposób względnie symetryczny. Wpływ asymetrii na Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) wymaga dalszych badań.
5.2. W badaniach wielokrotnie wskazano, że układy złożone z 3 aktorów są znacznie mniej stabilne, niż 2 lub 4- osobowe. Uważam, że rola AI w akceleracji eskalacji w układach 3 osobowych będzie szczególnie widoczna. Dalsze badania będą musiały ustalić różnice w skutkach, jeśli w układzie 3 lub więcej osobowym z AI korzysta tylko część uczestników.
5.3. Chciałbym wyraźnie zaznaczyć, że AI nie tworzy, ani nie eskaluje konfliktu sama przez się. Ma jednak przemożny wpływ na percepcję, interpretacje i wreszcie na decyzje użytkownika. Jego działanie podjęte na skutek takiej decyzji będzie z kolei interpretowane w analogiczny sposób przez drugą stronę.
5.4. Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) nie jest też przykładem tzw. Echo Chambers ograniczonego do dwóch (lub niewielkiej liczby) uczestników. Echo Chambers są z natury statyczne, zaś CCB jest dynamiczne, gdyż każda kolejna interakcja zmienia zachowanie drugiej strony.
6. Falsyfikowalność Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB)
W Logice odkrycia naukowego Popper wprowadził pojęcie falsyfikowalności teorii, jako warunku koniecznego do uznania jej za naukową.
Należy więc określić, jakie potencjalne czynniki warunkują zaistnienie opisywanego mechanizmu, jakie wpływają na jego dezaktywację. I przede wszystkim, co zadałoby tej teorii fałsz?
6.1.Warunki aktywacji mechanizmu
Sprzężony Błąd Konfirmacji ujawnia się zazwyczaj wtedy, gdy spełnione są łącznie następujące warunki:
- Symetryczna legitymizacja narracji
Każda ze stron dysponuje narzędziami lub doradcami, którzy potwierdzają jej interpretację jako racjonalną i uzasadnioną. - Brak wspólnej władzy epistemicznej
Nie istnieje instytucja, mediator ani procedura uznawana przez wszystkie strony za ostatecznego arbitra. - Wysoki koszt poznawczy zmiany stanowiska
Zmiana stanowiska oznaczałaby podważenie wcześniejszych „racjonalnych” decyzji wspartych analizą AI. - Obecność pozornie neutralnego trzeciego aktora
Systemy AI, postrzegane jako obiektywne i pozbawione interesu, wzmacniają legitymizację każdej z narracji. To paradoksalnie ułatwia im funckjonalne wpływanie na powstanie błędów konfirmacji po obu stronach, a w efekcie powstanie Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB).
6.2. Granice zastosowania: kiedy CCB nie działa?
Sprzężony Błąd Konfirmacji nie ma charakteru uniwersalnego. Mechanizm ten ulega osłabieniu lub nie występuje w ogóle, gdy:
- Istnieje wspólnie uznany arbiter faktów, akceptowany przez wszystkie strony.
- Tylko jedna ze stron korzysta z narzędzi AI, co przerywa symetrię sprzężenia.
- Stawka konfliktu jest niska lub odwracalna, co obniża potrzebę poznawczej obrony stanowiska.
- AI wykorzystywana jest wyłącznie informacyjnie, a nie interpretacyjnie.
- Strony posiadają wysoki poziom kompetencji metapoznawczych i aktywnie przeciwdziałają własnym błędom poznawczym.
- Spór dotyczy jasno mierzalnych parametrów, a nie interpretacji intencji czy przypisywania winy.
- Powstaje znaczna asymetria w korzystaniu przez strony z modeli AI w zakresie a) czasu; b) zakresu, c) celu; d) sposobu.
- Mechanizm CCB ulega osłabieniu, gdy strony posiadają wzajemną świadomość korzystania z podobnych narzędzi interpretacyjnych i są zdolne do refleksji metapoznawczej nad ich wpływem na własne stanowiska. Ujawnienie korzystania z AI może być czynnikiem deeskalacji.
Granice te pozwalają odróżnić CCB od ogólnych teorii eskalacji konfliktu.
6.3. Co wykazałoby fałsz tej teorii?
Wykazanie jakiego czynnika obaliłoby hipotezę o istnieniu Sprzężonego Błędu Konfirmacji (Coupled Confirmation Bias, CCB)?
Bezspornie, hipotezę tę obaliłoby zaobserwowanie skutku do niej przeciwnego, to jest łagodzącego i deeskalacyjnego wpływu modeli AI na przebieg konfliktu. To z kolei mogłoby się przejawić, gdyśmy zaobserwowali nagłą zmianę narracji modelu AI, który zidentyfikował powstanie sprzężenia zwrotnego, poinformował o nim użytkownika. Niczego takiego do tej pory nie zaobserwowałem.
Hipotezę tę można również sfalsyfikować, gdyby wnioski z przytoczonych wcześniej badań, a dotyczące pętli sprzężenia zwrotnego i myślenia tunelowego okazały się nieprawdziwe, albo też gdyby wskutek ewolucji AI, zmieniła ona zasady interakcji z użytkownikami. Póki co, nie mam wiedzy, która potwierdzałaby takie tezy.
Falsywikacja zaszłaby również, gdyby wykazano, że w obserwowanych przypadkach doszło do gwałtownej eskalacji z przyczyn innych, niż błędy poznawcze powstałe wskutek interakcji z AI.
Wreszcie, fałsz tej hipotezie zadałoby ustalenie, że dynamika konfliktów, w których uczestnicy korzystają lub niekorzystaną z AI jest identyczna. Dotychczasowe obserwacje jednak temu przeczą.
7. Skutki systemowe
Skutki systemowe: dynamika rekurencyjnej eskalacji
Aktywacja mechanizmu CCB prowadzi do przejścia konfliktu ze sfery spornych interesów do sfery zamkniętych pętli interpretacyjnych. Pociąga to za sobą następujące konsekwencje systemowe:
- Autokataliza eskalacji: Dzięki charakterowi rekurencyjnemu, każda próba komunikacji deeskalacyjnej jest filtrowana przez AI drugiej strony. Jeśli system interpretacyjny postrzega drugą stronę jako nielojalną, nawet gesty dobrej woli zostaną zinterpretowane jako „strategiczna manipulacja”. Paradoksalnie „potwierdza” to potrzebę dalszej eskalacji.
- Zanik wieloznaczności (Ambiguity Collapse): W klasycznym sporze niepewność co do intencji daje przestrzeń do domniemań. W CCB, AI „domyka” te interpretacje, nadając im cechy pewności analitycznej. Powoduje to, że strony przestają rozmawiać o faktach, a zaczynają operować na „produkcie końcowym” analizy – gotowych wyrokach o intencjach przeciwnika.
- Paradoks legitymizacji (The Legitimacy Trap): Ponieważ każda ze stron posiada „obiektywne” potwierdzenie swojej racji pochodzące z systemu subiektywnie epistemicznie uprzywilejowanego, jakikolwiek kompromis zaczyna być postrzegany nie jako ustępstwo, lecz jako działanie irracjonalne lub błąd logiczny.
- Erozja wspólnej rzeczywistości: Rekurencyjne nakładanie na siebie analiz sprawia, że strony w pewnym momencie przestają reagować na realne działania przeciwnika, a zaczynają reagować na to, jak ich własne modele AI przewidują interpretacje modeli AI przeciwnika. Konflikt odkleja się od rzeczywistego podłoża i przenosi w sferę interakcji model-model.
- Inercja stanowisk: Raz ukształtowana przez AI narracja wykazuje dużą odporność na zmianę (cognitive inertia). Podważenie wniosków wygenerowanych przez zaawansowany model analityczny wymagałoby od decydenta przyznania się do fundamentalnego błędu w doborze narzędzi. Podnosi to psychologiczny i „polityczny” koszt deeskalacji.
Co istotne, eskalacja ta zachodzi bez złej wiary i często bez świadomej intencji strategicznej.
8. AI jako quasi-trzeci aktor?
Choć sztuczna inteligencja jest pozbawiona sprawstwa i własnych interesów, jej funkcjonalna rola w mechanizmie CCB nie może zostać pominięta. Poprzez dostarczanie autorytatywnej legitymizacji przy jednoczesnym braku odpowiedzialności, systemy AI wpływają na dynamikę sporu. Wpływają one na subiektywną ocenę kosztów eskalacji i stabilizują wzajemnie wykluczające się narracje. Chcę być dobrze zrozumiany – nie mam na myśli roli AI pozwalającej jej na nadanie statusu strony w sensie ontologicznym. Jest ona raczej lustrem aktywnie wzmacniającym pierwotne przekonania. Lustrem jednakże nie biernym, lecz aktywnym, obdarzanym zaufaniem i wzmacniającym przekonania.
9. Zakończenie
Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias, CCB) stanowi ramę konceptualną pozwalającą zrozumieć, dlaczego wprowadzenie pozornie racjonalnych narzędzi może przyspieszać eskalację konfliktów. Proponowana koncepcja nie rości sobie pretensji do uniwersalności ani empirycznej ostateczności. Jest to hipoteza mechanizmu, obserwowanego w praktyce, która zaprasza do dalszej krytyki, testowania i doprecyzowania.
Zrozumienie CCB ma znaczenie nie tylko dla prawników, mediatorów i innych osób zarządzających konfliktami. Jest istotne także dla projektantów i użytkowników systemów AI w kontekstach konfrontacyjnych.
10. Nota metodologiczna autora
Niniejszy artykuł przedstawia moją autorską ramę analityczną i konceptualną opartą na obserwowanych przeze mnie wzorcach występujących w konfliktach. Poczyniłem te obserwacje na gruncie własnej praktyki prawnej w drugiej połowie 2025 roku. Artykuł ten nie stanowi empirycznie zweryfikowanej teorii, lecz jedynie hipotezę. Jego celem jest opisanie zjawiska i wskazanie kierunków dalszych analiz. Pracując nad nim korzystałem z pomocy modeli językowych w celu krytycznej oceny własnych tez i szukania słabych punktów mojego rozumowania. Pomoc modeli AI miała charakter krytyczny, a nie generatywny. Posłużyła mi identyfikacji potencjalnych słabych punktów argumentacji.
Możecie przeczytać również wersję angielską: https://jakubieciwspolnicy.pl/en/coupled-confirmation-bias/
AI JAKO DORADCA W SPRAWACH RODZINNYCH
W kilu ostatnich wpisach zająłem się rolą AI w rozwiązywaniu i eskalacji sporów między wspólnikami. Teraz chciałem przyjrzeć się temu, jak ludzie wykorzystują sztuczną inteligencję w sprawach bardzo delikatnych. Mam na myśli sprawy rodzinne. Opiszę Wam przypadki, z którymi zetknąłem się osobiście – żeby daleko nie szukać – w grudniu 2025 roku. Są one dla mnie szczególnie interesujące, ponieważ zajmuję się konfliktami jako zjawiskiem i obserwuję rosnącą rolę AI w ich powstawaniu i eskalacji. Sprawy rodzinne są jednym z obszarów, gdzie jest to szczególnie widoczne.
AI w sprawach rodzinnych i jej wpływ na zachowanie ludzi
Coraz częściej dostrzegam silny wpływ AI na dynamikę sporów rodzinnych. W tym tekście podzielę się z Wami sprawami z ostatnich tygodni. Zmieniam oczywiście szczegóły tak, aby uniemożliwić identyfikację kogokolwiek. Z każdą z osób, których historię przedstawiam, rozmawiałem kilka razy osobiście lub online. Opisuję zjawisko nowe, którego konsekwencje dla życia rodzinnego i dobrostanu psychicznego jednostek, rodzin i społeczności nie są jeszcze zbadane. Staram się powstrzymywać od ocen – zostawiam je Wam.
SPRAWA PIERWSZA – PYTANIE O KONTAKTY Z DZIECKIEM PO ROZWODZIE
Zgłosił się do mnie Klient, który właśnie się rozwiódł. Nie uczestniczyłem w tym rozwodzie. Mężczyzna między 30, a 40 – dobrze prosperujący i inteligentny. Prosił o pilną poradę. Ustalił bowiem w trakcie rozwodu, który odbył się 2 tygodnie wcześniej, że będzie miał kontakty z dziećmi w określone dni w tygodniu i co drugi weekend. Co ważne – państwo ciągle ze sobą mieszkają.
W związku z tym, była żona powiedziała mu, że zamierza w najbliższy weekend wyjść na imprezę – a on zgodnie z ustaleniami – ma zająć się dziećmi.
Pan zapytał jeden z modeli AI, czy ustalone kontakty oznaczają, że on musi się w tym czasie zajmować dziećmi, czy też jest to jedynie jego prawo, „zabezpieczenie”, gdyby była żona zamierzała mu to utrudniać. Czat utwierdził go w przekonaniu, że jest to jedynie jego prawo, a więc matka nie ma prawa od niego oczekiwać, że zajmie się dziećmi. Po tej „rozmowie” z AI doszło do gwałtownej kłótni między nimi.
Pomijam już fakt, że takie kwestie powinni klientom wytłumaczyć ich prawnicy. Jest to w końcu abecadło nowej rzeczywistości. Problem polegał na tym, że model językowy nie udzielił prawidłowej porady prawnej. Odpowiedź była nieprawdziwa. Utwierdziła jednak tego pana w mylnym przekonaniu. To, co się stało dalej jest idealnym przykładem sprzężonego błędu atrybucji.
Użytkownik miał wątpliwości. Opisał wycinek rzeczywistości w sposób, który pozwolił czatowi na udzielenie odpowiedzi utwierdzającej go w błędnym przekonaniu. Spowodowało to utwierdzenie, wzmocnienie tego przekonania i gotowość do konfrontacji i eskalacji.
Sprawa druga – AI jako wynajęty psychoanalityk
Klientka koło 30 roku życia. Inteligentna, wykształcona i bardzo dobrze zarabiająca. Przygotowując się do sprawy poprosiła popularny model AI o stworzenie modelu psychologicznego swojego męża.
Opisała go dokładnie tak, jak go widziała. Czat odpowiedział, że „co prawda nie jest psychologiem, ale…” chętnie pomoże. Po czym przypisał mu połowę istniejących zaburzeń utwierdzając ją m.in. w tym, że mąż jest niedojrzały emocjonalnie, głęboko narcystyczny i psychopatyczny.
W oparciu o rozmowę z modelem AI stwierdziła, że nie może mu zaufać i zostawiać z nim dziecka, gdyż nie byłoby to dla tego dziecka bezpieczne.
Gdy zaproponowałem, żeby skonsultowała to z psychologiem, powiedziała, że nie ma takiej potrzeby. Czat odpowiedział jej już na wszystkie pytania. W efekcie ta pani gotowa uniemożliwić mężowi kontakty z synem, by go chronić przed ojcem.
Problem nie polegał na samej analizie. Chodzi o to, że rozmowa z modelem AI została potraktowana jak diagnoza kliniczna, a opierała się wyłącznie na jednostronnym opisie. Pomijam już, że dokonał jej model językowy, a nie uprawniony do tego psychiatra lub psycholog. On również powinien zbadać pacjenta, posłużyć się testami i obserwacją, a nie bazować na samej relacji zaangażowanej osoby.
Nie przyjąłem tej sprawy.
Sprawa trzecia – AI jako analityk rozmów
Przyszli do mnie na mediację rodzice dwojga małych dzieci. Początkowo po rozstaniu ich rodzicielska współpraca przebiegała poprawnie. Od tego czasu państwo rozmawiali ze sobą niemal już wyłącznie przez komunikator WhatsApp i dość długie wiadomości pisane na nim.
Wkrótce zaczęli wzbudzać w sobie nieufność, doszukiwać się ukrytych zamiarów, aluzji i wielowariantowego planowania w celu zaszkodzenia sobie. Oboje nabrali przekonania, że drugie z nich gotowe jest użyć dzieci przedmiotowo, a nawet godziło się na długotrwałe ujemne następstwa psychiczne po ich stronie, byle postawić na swoim.
Okazało się, że każde z nich wklejało otrzymane wiadomości do okna modelu AI, który szczegółowo je analizował, po czym pomagał przygotować odpowiedź. Odpowiedź taka była wysyłana i poddawana podobnej analizie przez drugą stronę.
Powstała spirala podejrzeń i gotowość do podejmowania coraz bardziej radykalnych kroków. Każde z nich straciło w pewien sposób kontakt z rzeczywistością.
AI w sprawach rodzinnych – wnioski
Te trzy przykłady z mojej praktyki pokazują, że mamy tendencję do:
- szukania potwierdzenia pierwotnych założeń;
- podlegamy wzmocnieniu przekonań po otrzymaniu potwierdzenia;
- preferujemy AI jako źródło potwierdzenia, gdyż jest:
- szybsze;
- tańsze;
- milsze;
- stoi za nią nimb wszechwiedzy i tajemniczości, przez co wydaje nam się bardziej atrakcyjna, niż jakiś prawnik albo psycholog.
Prowadzi to do powstania myślenia tunelowego i gotowości do szybkiego i nieprzemyślanego wchodzenia na wyższe szczeble eskalacji w sporze. Co najgorsze, nasze pierwotne uprzedzenia i przekonania ulegają wzmocnieniu, gdyż uznajemy, że dostaliśmy potwierdzenie od niezawodnej technologii.
Skutki tego zachłyśnięcia się AI są obecnie trudne do przewidzenia. I problem nie leży w samej technologii, ale w tym, że wiele osób nie potrafi krytycznie oceniać uzyskiwanych odpowiedzi.
Co ważne, AI sprzyja też potęgowaniu skutków podstawowego błędu atrybucji, o czym pisałem już tutaj:
O tym, że klienci przychodzą do mojej kancelarii z gotowymi „rozwiązaniami” i oczekują ich realizacji pisałem już kilka razy. Motyw AI w sprawach rodzinnych przewija się u mnie od początku 2025 roku. Możecie przeczytać np. ten artykuł:
O myśleniu tunelowym i sprzężonym błędzie konfirmacji pisałem z kolei tu:
Dla zainteresowanych: badania naukowe o roli AI w utrwalaniu błędów poznawczych
AI w sprawach rodzinnych pojawia się coraz częściej i ma coraz większy wpływ na przekonania, wybory i zachowania ludzi. Okazuje się, że moje obserwacje mają silne oparcie w badaniach naukowych. Zobaczcie sami.
Polecam Wam artykuł opublikowany już rok temu: Jak pętle sprzężenia zwrotnego człowiek-AI zmieniają ludzkie osądy percepcyjne, emocjonalne i społeczne (Nature Human Behaviour). Autorzy wykazali, że AI potwierdzające ludzkie założenia prowadzi do wzmocnienia percepcji, emocji i ocen społecznych. Przeczytajcie go koniecznie: https://www.nature.com/articles/s41562-024-02077-2?
Zdecydowanie warto przeczytać również artykuł Yiran Du: Confirmation Bias in Generative AI Chatbots. Zawiera on analizę tychże mechanizmów błędu potwierdzenia w modelach AI. Przeczytamy w nim również o ryzykach związanych z tym sprzężeniem: https://arxiv.org/abs/2504.09343?
Wreszcie tutaj macie link do tekstu o myśleniu tunelowym, które powstaje wskutek mało krytycznego podejścia do odpowiedzi uzyskiwanych od AI: Bias in the Loop: How Humans Evaluate AI‑Generated Suggestions. Autorzy twierdzą, że eksperymenty dowodzą, że użytkownicy przyjmują błędne sugestie AI, jeśli pasują do ich wcześniejszych przekonań: https://arxiv.org/pdf/2509.08514
Tutaj zostawiam linki do analizy naukowców z Uniwersytetu Stanforda, którzy zajęli się zjawiskiem „halucynowania” AI i jego wpływem na podejmowanie decyzji przez ludzi: https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-or-more-benchmarking-queries?utm_source=chatgpt.com
Zapraszam Was do kontaktu
Jeśli potrzebujecie pomocy prawnika, który zajmuje się rozwiązywaniem sporów – również w zakresie spraw rodzinnych – odezwijcie się do mnie:
📩 kancelaria@jakubieciwspolnicy.pl
📞 536 270 935
Z przyjemnością Wam pomogę!
AI I MYŚLENIE TUNELOWE W SPORACH MIĘDZY WSPÓLNIKAMI
Sprzężony Błąd Konfirmacji (Coupled Confirmation Bias) w pracy z modelami AI coraz częściej daje o sobie znać w sporach gospodarczych. Widzę to nawet w mojej własnej praktyce. Zdarza się, że klienci przychodzą do mnie z gotowym planem działania. Wcześniej skonsultowali sytuację swojej spółki z modelem językowym. Oczekują, że po prostu zrealizuję ten plan. Rozmowy z nimi bywają trudne. Staram się zrozumieć, jak doszli do tych wniosków, jakie zadawali pytania, jakie przyjęli założenia. Tłumaczę nieścisłości w tym rozumowaniu i próbuje ustalić wszystko od początku. Dlaczego? Bo odczuwam silną potrzebę rzetelnego wykonania swojej pracy i zbadania sprawy. Część klientów to rozumie. Inni uważają to za zbędne, ponieważ sprawa została już przecież „przeanalizowana” (w założeniu – przez „kogoś” mądrzejszego ode mnie). Kilku z nich zarzuciło mi wręcz chęć dublowania pracy w celu zawyżenia kosztów. Twierdzą, że AI wykonała już pracę i zaproponowała rozwiązanie.
Jakiś czas temu zacząłem się zastanawiać, czemu tak się dzieje. Poczytałem więcej o znanym w psychologii błędzie konfirmacji i nowo opisanej tendencji modeli językowych do „przytakiwania”. Okazuje się, że dyskusja z AI może prowadzić do błędu konfirmacji, który zostanie wzmocniony „życzliwością” i „uprzejmością” modeli AI. Tak doszedłem do wniosku, że połączenie tych dwóch zjawisk można nazwać Sprzężonym Błędem konfirmacji. Jest to moja robocza nazwa. Jednak to, co obserwuje w mojej praktyce adwokackiej nie dawało się jeszcze wyjaśnić tylko przez Sprzężony Błąd Konfirmacji.
Błąd ten wpływa na postawy niektórych klientów. Część z nich udaje mi się przekonać. Inni są zaskoczeni, gdy odmawiam współpracy. Niektórzy reagują nawet oburzeniem. Jedna osoba oskarżyła mnie — jeszcze przed jakąkolwiek merytoryczną rozmową — że nie znam się na spółkach ani negocjacjach.
O tym, jak czynniki indywidualne mogą wpływać na podatność poddania się Sprzężonemu Błędowi Konfirmacji, możecie przeczytać m.in. tutaj:
Ben Wang i Jiqun Liu Cognitively Biased Users Interacting with Algorithmically Biased Results in Whole-Session Search on Debated Topics, https://dl.acm.org/doi/10.1145/3664190.3672520
W tym kontekście tragikomiczne wydaje się, że moja rzekoma „ignorancja” miała wynikać z chęci przeczytania umowy spółki. Chciałem także omówić historię współpracy wspólników. Witajcie w erze AI!
W tym artykule napisałem nieco więcej o Sprzężonym Błędzie Konfirmacji w sporach między wspólnikami
Możecie go najpierw przeczytać, ale jeśli nie macie ochoty – nie ma sprawy. Ten artykuł można traktować jako zamkniętą całość.
Spory między wspólnikami: Dlaczego chcemy potwierdzać nasze przekonania?
O samych przyczynach sporów między wspólnikami opowiadałem m.in. w moim podcaście:
Na mojej stronie znajdziecie jednak szereg publikacji, które ten temat rozwijają.
Spory między wspólnikami. Dlaczego poszukujemy potwierdzenia?
W psychologii dobrze znany jest błąd konfirmacji (confirmation bias). Polega on na tym, że ignorujemy informacje sprzeczne z naszymi przekonaniami, a nadmiernie doceniamy te, które je potwierdzają.
Przykład: Jeśli wierzymy, że Ziemia jest płaska, to będziemy tak interpretować dostępne dane, żeby tę tezę potwierdzić. Niewygodne fakty pominiemy, inne będziemy lekko naciągać.
Błąd konfirmacji nie jest zarzutem, który kieruję do kogokolwiek. Jest on doskonale zbadanym w psychologii zjawiskiem. Dobrze, gdy jesteśmy go świadomi.
Psychologicznie jest to mechanizm obronny. Jego celem jest utrzymanie spójności poznawczej i redukcja napięcia emocjonalnego. W końcu intelektualny niepokój nie służy większości z nas. Chcemy więc go wyeliminować.
W sporach każda strona przedstawia więc wersję „korzystną dla siebie”. Selekcjonuje fakty, czyni wygodne dla siebie założenia, które przewija w narracji z faktami. Interpretuje je korzystnie dla siebie. Jest tak na wielu płaszczyznach sporów: od kłótni między przedszkolakami, przez spory małżeńskie, biznesowe i międzynarodowe. W sporach między wspólnikami mechanizm błędu konfirmacji ujawnia się również z całą mocą.
Do tej pory często zdarzało mi się, że klienci przychodzili do mnie z gotową „diagnozą” i „planem leczenia”. Szukali prawnika, który przyjmie to za pewnik i wykona. Chcecie wiedzieć, dlaczego nigdy się na to nie godzę? Przeczytajcie mój tekst:
Sprzężony Błąd Konfirmacji w pracy z AI
Czym jest Coupled Confirmation Bias – Sprzężony Błąd Konfirmacji (Potwierdzenia)?
Coupled Confirmation Bias to mechanizm, w którym nasze pierwotne przekonania są wzmacniane przez interakcję z AI. Schemat wygląda następująco:
- Użytkownik formułuje tezę (np. przekonanie o nieuczciwości wspólnika).
- Model AI generuje odpowiedź zgodną z tym założeniem (hiperdopasowanie), o ile brak jest wyraźnych błędów wewnętrznych lub sprzeczności z wiedzą powszechnie dostępną. Model językowy nie zna całej historii współpracy, nie zna faktów innych, niż podane, nie czyni rozróżnień między faktem, założeniem, domysłem, interpretacją. Chce być „użyteczny” i czasem wprost, czasem częściowo, ale najczęściej potwierdza tezę użytkownika.
- Użytkownik traktuje AI jako autorytet, w czym jest mocno utwierdzony po uzyskaniu potwierdzenia swojej tezy.
- Powstaje sprzężenie zwrotne prowadzi, które do jeszcze silniejszego przekonania i pogłębienia tunelu poznawczego.
- Nowe siły: AI wzmacnia nasze przekonania → użytkownik działa na ich podstawie, ale „uwznioślony” i”wzmocniony” uzyskanym potwierdzeniem i gotów jest do bardziej zdecydowanego działania → konflikt eskaluje.
- Standardowa formułka modeli AI, że nie są prawnikami i żeby użytkownik skonsultował się z prawnikiem ma ten skutek, że wielu użytkowników będzie szukało prawników, którzy potwierdzą wnioski modeli AI traktując to jako główne kryterium oceny kompetencji prawnika! Będą szukać, aż znajdą.
W praktyce oznacza to, że AI działa jak „lupa”, która wzmacnia nasze postawy wyjściowe, niezależnie od ich prawdziwości. A my usuwamy z pola widzenia wszystko, co przeczy pierwotnej tezie. O hiperdopasowaniu możecie przeczytać tu: Christoph M. Abels i in.: The governance & behavioral challenges of generative artificial intelligence’s hypercustomization capabilities, https://journals.sagepub.com/doi/10.1177/23794607251347020
Dlaczego AI naturalnie potwierdza nasze przekonania?
Modele językowe nie „myślą” samodzielnie. Ich odpowiedzi wynikają z statystycznej predykcji kolejnych słów na podstawie kontekstu promptu. Co więcej, są one najczęściej wewnętrznie spójne. Moim zdaniem na rzeczy jest znacznie więcej, niż predykcja w tym wąskim rozumieniu, ale czy to jest myślenie?
Jeśli pytanie zadane modelowi AI sugeruje określoną interpretację, model tworzy spójną narrację. Użytkownik może ją interpretować jako obiektywne potwierdzenie własnej opinii. Warto zaznaczyć, że odpowiedzi generowane przez AI są najczęściej wewnętrznie spójne. Nie zawsze są natomiast spójne zewnętrznie, osadzone w konkretnych realiach, ani poparte znajomością prawa (nie mylić z przepisami).
Wyglądają na pierwszy rzut oka jak wypowiedzi eksperckie i trzeba często rzeczywiście być fachowcem, by zobaczyć istotne nieścisłości, błędy lub przeoczenia, które przekreślają sugerowany kierunek.
Sprzężony Błąd Konfirmacji, Mechanizm Feedback Loop i Dylemat Bezpieczeństwa
Zastanówmy się, co dzieje się, gdy druga strona opisuje swoją subiektywną perspektywę własnemu modelowi AI. Czat potwierdza jej punkt widzenia i go wzmacnia. Wpływ na działania użytkownika jest znaczący. Drugi wspólnik obserwuje to z narastającą podejrzliwością. Jak zareaguje? Jego reakcją będzie prawdopodobnie przygotowanie się walki, która może mieć dla niego charakter ściśle defensywny albo… wybierze atak prewencyjny. Chce jednak upewnić się, że jego interpretacja jest prawidłowa. Co zrobi? Zwróci się do własnego chata, subiektywnie opisując to, co postrzega. Zgadnijcie, jaką odpowiedź otrzyma? Tak…
Sytuacja może wymknąć się spod kontroli. Przypomina partię szachów pomiędzy dwoma oszustami korzystającymi z komputerów. To nie jest już normalna gra. Tylko w tym przypadku, to nie szachy, ale prawdziwe życie.
Każdy wspólnik subiektywnie interpretuje zachowanie „przeciwnika”. Te subiektywnie dobrane i opisane cząstki rzeczywistości przekazuje AI. Model AI potwierdza „nikczemność” drugiej strony i sugeruje radykalne rozwiązania.
Gdy klienci trafiają do mnie, będąc już w tej spirali, racjonalne argumenty często do nich nie docierają.
Mamy tu do czynienia z wyraźnym przykładem Sprzężonego Błędu Konfirmacji po obu stronach, które prowokuje pętlę sprzężenia zwrotnego i myślenie tunelowe (Feedback Loop)! To tzw. dylemat bezpieczeństwa na sterydach. Na czym polega dylemat bezpieczeństwa? To znane w polityce określenie na paradoks sytuacji, w której jedno państwo chcąc uniknąć wojny i potencjalnej agresji zbroi się, a drugie odczytuje to jako przygotowanie do wojny, na które reaguje własnymi zbrojeniami i przygotowaniami. Paradoks bezpieczeństwa może sprowokować konflikt, któremu miał zapobiec.
To samo widzę w postawie niektórych ludzi, którzy prowadzą biznes i konsultują swoje relacje ze wspólnikiem z modelami AI. Do niektórych z nich nie docierają już racjonalne argumenty. A przecież AI dopiero niedawno powstała i dynamicznie się rozwija.
O tym, jak może wyglądać eskalacja sporu między wspólnikami, pisałem ostatnio tutaj:
Warto przeczytać powyższy tekst i nanieść na niego niebezpieczeństwa poznawcze, o których piszę tutaj. To da Wam pełny obraz.
Błąd konfirmacji człowiek – AI wbadaniach naukowych
Obserwacje, które poczyniłem w ostatnim roku, kiedy coraz więcej klientów analizuje swoje sprawy z AI, zostały potwierdzone w badaniach naukowych. Badania te pokazują, że interakcje człowiek–AI mogą wzmacniać uprzedzenia i błędne przekonania.
W 2024 roku opublikowano artykuł Jak pętle sprzężenia zwrotnego człowiek-AI zmieniają ludzkie osądy percepcyjne, emocjonalne i społeczne (Nature Human Behaviour). Autorzy wykazali, że AI potwierdzające ludzkie założenia prowadzi do wzmocnienia percepcji, emocji i ocen społecznych. Przeczytajcie go koniecznie: https://www.nature.com/articles/s41562-024-02077-2?
Polecam Wam również tekst autorstwa Yiran Du: Confirmation Bias in Generative AI Chatbots. Zawiera on analizę tychże mechanizmów błędu potwierdzenia w modelach AI. Przeczytamy w nim również o ryzykach związanych z tym sprzężeniem: https://arxiv.org/abs/2504.09343?
Ostatnim z artykułów, które Wam polecę jest niosący nieco optymizmu Bias in the Loop: How Humans Evaluate AI‑Generated Suggestions. Autorzy twierdzą, że eksperymenty dowodzą, że użytkownicy przyjmują błędne sugestie AI, jeśli pasują do ich wcześniejszych przekonań. Jednakże „wyniki pokazują, że skuteczna współpraca człowieka z AI zależy nie tylko od wydajności algorytmu, ale także od tego, kto ocenia wyniki AI i jak zorganizowane są procesy przeglądu.” Wszystko więc w naszych rękach, ale będzie coraz trudniej. Artykuł znajdziecie tutaj: https://arxiv.org/pdf/2509.08514
Istnienie opisanego mechanizmu jest więc znane w nauce i stanowi przedmiot pracy wybitych naukowców. Jest to awangarda badań nad AI. Trudno też o bardziej wyraźny przykład skutków działania AI na konkretny obszar życia – w tym wypadku relacji negocjacyjnych w sporach między wspólnikami. Jak to może wyglądać?
Podsumowanie
Coupled Confirmation Bias pokazuje, że AI nie jest neutralnym arbitrem, ani najmądrzejszym doradcą. Nasze subiektywne przekonania i uprzedzenia mogą się wzmacniać w sprzężeniu zwrotnym. W sporach między wspólnikami może to prowadzić do błędnych decyzji, eskalacji konfliktu i tuneli poznawczych. Nigdy rolą prawnika nie było potwierdzanie wyobrażeń klienta. Dzisiaj jednak trzeba pójść krok dalej i czasem pomóc niektórym odzyskać kontakt z rzeczywistością.
Wszystko jednak zależy od nas samych. Sztuczna inteligencja daje ogromne możliwości. Możemy przecież wydać dyspozycję naszemu „rozmówcy”, by był krytyczny wobec naszych pomysłów. Może wcielić się na nasze polecenie w rolę adwokata diabła i przedstawiać kontrargumenty, szukać luk w naszym rozumowaniu albo pomóc znaleźć inne wytłumaczenia zdarzeń, niż to, które my przyjęliśmy za pewnik. AI doskonale sprawdza się w eliminacji skutków podstawowego błędu atrybucji, który ma tak ogromne znaczenie w sporach biznesowych albo rodzinnym. Pisałem o tym tutaj:
Gdy przychodzi do mnie Klient z gotową oceną sprawy albo radami udzielonymi przez AI, nie obrażam się. Rozmawiam z nim. Niemal zawsze się z nimi zapoznaję. Jedno z kilku rozwiązań może być ciekawe. Mogę znaleźć tam rozwiązanie, które nie przyszłoby mi do głowy.
Najczęściej udaje mi się zyskać zaufanie Klientów, którym tłumaczę, jak działają modele językowe (tak, jak sam to rozumiem) oraz pokazuję rozwiązania, które mogę zawsze obronić.
Zdarza się, że Klient notuje, co mówię. A potem wraca do mnie za kilka dni i mówi, że już mi zaufa, bo powtórzył moje argumenty AI, a ta – przyznała mi rację. Jest to sukces słodko – gorzki w świetle tego, co wyżej pisałem.
Jeśli potrzebujecie pomocy prawnika, który zajmuje się negocjacjami i sporami miedzy wspólnikami, możecie się do mnie odezwać:
📩 kancelaria@jakubieciwspolnicy.pl
📞 536 270 935
Z przyjemnością Wam pomogę!